A Fog Island Tavern conversation
about defusing the adversarial aspect of the Argumentative Model of Planning
Thorbjoern Mann 2015
(The Fog Island Tavern: a figment of imagination
of a congenial venue for civilized conversations
about issues, plans and policies of public interest)
– Hi Vodçek, how’s the Tavern life this morning? Fog lifting yet?
– Hello Bog-Hubert, good to see you. Coffee?
– Sure, the usual, thanks. What’s with those happy guys over there — they must be drinking something else already; I’ve never seen them having such a good time here?
– No, they are just having coffee too. But you should have seen their glum faces just a while ago.
– What happened?
– Well, they were talking about the ideas of our friend up at the university, about this planning discourse platform he’s proposing. They were bickering about whether the underlying perspective — the argumentative model of planning — should be used for that, or some other theory, systems thinking or pattern language approaches. You should have been there, isn’t that one of your pet topics too?
– Yes, sorry I missed it. Did they get anywhere with that? What specifically did they argue about?
– It was about those ambitious claims they are all making, about their approach being the best foundation for developing tools to tackle those global wicked problems we are all facing. They feel that those claims are, well, a little exaggerated, while accusing each other’s pet approach of being far from as effective and universally applicable as they think. Each one missing just the main concerns the other feels are the most important features of their tool. And lamenting the fact that neither one seems to be as widely accepted and used as they think it deserves.
– Did they have any ideas why that might be?
– One main point seemed to be the mutual blind spot that the Argumentative Model, besides being too ‘rational’ and argumentative for some people, and not acknowledging emotions and feelings, did not accommodate the complexity and holistic perspective of systems modeling (in the view of the systems guys), while the systems models did not seem to have any room for disagreements and argumentation, from the point of view of your argumentative friends.
– Right. I am familiar with those complaints. I don’t think they are all justified, but the perceptions that they are need to be addressed. We’ve been working on that.
– Good. Another main issue they were all complaining about — both sides — was that there currently isn’t a workable platform for the planning discourse, even with all the cool technology we now have. And therefore some people were calling for a return to simple tools that can be used in actual meeting places where everybody can come and discuss problems, plans, issues, policies. The ‘design tavern’ that Abbé Boulah kept talking about, remember?
– Yes. It seemed like a good idea, but only for small communities that can meet and interact meaningfully in ‘town hall’- kind places. Like his Rigatopia thing, as long as that community stays small enough.
– Well, they seemed to get stuck in gloom about that issue for a while, couldn’t decide which way to go, and lamenting the state of technology for both sides. That’s when Abbé Boulah showed up for a while, and turned things around.
– How did he do that?
– He just reminded them of the incredible progress the computing and communication technology has seen in the last few decades, and suggested that they might think about how that progress might have been focused on the wrong problems, or simply not getting around to the real task of their topic — planning discourse support — yet. Told them to explore some opportunities of the technology – possibilities already realized by tools already on the market or just as feasible but not yet produced. He bought them a round of his favorite Slovenian firewater and told them to brainstorm crazy ideas for new inventions for that cause, to be applied first in his Rigatopia community experiment on that abandoned oil rig. That’s what set them off. Boy, they are still having fun doing that.
– Did they actually come up with some useful concepts?
– Useful? Don’t know about that. But there were some wild and interesting ideas I heard them toss around. Strangely, most of them seemed about tech gizmos. They seem to think that the technical problem of global communication is just about solved — messages, information can be exchanged instantaneously all over the world, and that concepts like Rittel’s IBIS provides an appropriate basis for organizing, storing, retrieving that information, and that the missing things have to do with the representation, display, and processing the contributions for decision-making: analysis and evaluation.
– Do you have an example of ideas they discussed?
– Plenty. For the display issue, there was the invention of the solar-powered ‘Googleglass-Sombrero’ — taking the Google glass idea a step further by moving the internet-connected display farther away from the eye, to the rim of a wide sombrero, so that several display maps can be seen and scanned side by side, not sequentially. Overview, see? Which we know today’s cell-phones or tablets don’t do so well. There was the abominable ‘Rollupyersleeve-watch’. It is actually a smartphone, but would have an expandable screen that can be rolled up to your elbow so you can see several maps simultaneously. Others were still obsessed with making real places for people to actually meet and discuss issues, where the overall discourse information is displayed on the walls, and where they would be able to insert their own comments to be instantly added and the display updated. ‘Democracy bars’, in the tradition of the venerable sports bars. Fitted with ‘insect-eye’ projectors to simultaneously project many maps on the walls of the place, with comments added on their own individual devices and uploaded to the central system.
– Abbé Boulah’s ‘Design Tavern’ brought into the 21st IT age. Okay!
– Yes, that one was immediately grabbed by the corporate – economy folks: Supermarkets offering such displays in the cafe sections, with advertisement, as added P/A attractions…
– Inevitable, I guess. Raises some questions about possible interference with the content?
– Yes, of course. Somebody suggested a version of the old equal-time rule: that any such ad had to be immediately accompanied by a counter-ad of some kind, to ‘count’ as a P/A message.
– Hmm. I’d see a lot of fruitless lawsuits coming up about that.
– Even the evaluation function generated its innovative gizmos: There was a proposal for a pen (for typing comments) with a sliding up-down button that instantly lets you send your plausibility assessment of proposed plans or claims. It was instantly countered by another idea, of equipping smartphones with a second ‘selfie-camera’ that would read and interpret you facial expressions when reading a comment or argument: not only nodding for agreement, shaking your head to signal disagreement, but also reading raised eyebrows, frowns, smiles, confusion, and instantly sending it to the system, as instant opinion polls. That system would then compute the assessment level of the entire group of participants in a discussion, and send it back to the person who made a comment, suggesting more evidence, or better justification etc.
– Yes, there are some such possibilities that a kind of ‘expert system’ component could provide: not only doing some web research on the issues discussed, but actually taking part in the discussion, as it were. For example, didn’t we discuss the idea of such a system scanning both the record of discussion contributions and the web, for example for similar cases? I remember Abbé Boulah explaining how a ‘research service’ of such a system could scan the data base for pertinent claims and put them together into pro and con arguments the participants hadn’t even thought of yet. Plus, of course, suggesting candidate questions about those claims that should be answered, or for which support and evidence should be provided, so people could make better-informed assessments of their plausibility.
– I’m glad you said ‘people’ making such assessments. Because contrary to the visions of some Artificial Intelligence enthusiasts, I don’t think machines, or the system, should be involved in the evaluation part.
– Hey, all their prowess in drawing logical conclusions from data and stored claims should be kept from making valuable contributions: are you a closet retro-post-neoluddite? Of course I agree: especially regarding the ought-claims of the planning arguments, the system has no business making judgments. But the system would be ‘involved’, wouldn’t it? Processing and calculation of participants’ evaluation results? In taking the plausibility and importance judgments, and calculating the resulting argument plausibility, argument weights, and conclusion plausibility, as well as the statistics of those judgments for the entire group of participants?
– You are right. But those results should always just be displayed for people to make their own final judgments in the end, wasn’t that the agreement? Those calculation results should never be used as the final decision criterion?
– Yes, we always emphasized that; but in a practical situation it’s a fine balancing act. Just like decision-makers were always tempted to use some arbitrary performance measure as the final decision criterion, just because it was calculated from a bunch of data, and the techies said it was ‘optimized’. But hey, we’re getting into a different subject here, aren’t we: How to put all those tools and techniques into a meaningful design for the platform, and a corresponding process?
– Good point. Work to do. Do you think we’re ready to sketch out a first draft blueprint of that platform, even if it would need tools that still have to be developed and tested?
– Worth a try, even if all we learn is where there are still holes in the story. Hey guys, why don’t you come over here, let’s see if we can use your ideas to make a whole workable system out of it: a better Planning Discourse Support System?
– Hi Bog-Hubert. Okay, if you feel that we’ve got enough material lined up now?
– We’ll see. How should we start? Does your Robert’s Rules expert have any ideas? Commissioner?
– Well, thanks for the confidence. Yes, I do think it would be smart to use the old parliamentary process as a skeleton for the process, if only because it’s fairly familiar to most folks living in countries with something like a parliament. Going through the steps from raising an issue to a final decision, to see what system components might be needed to support each of those steps along the way, and then adding what we feel are missing parts.
– Sounds good. As long as Vodçek keep his bar stocked, we can always go back to square one and start over if we get stuck. So how does it start?
– I think there are several possible starting points: Somebody could just complain about a problem, or already make a proposal for how to deal with it, part of a plan. Or just raise a question that’s part of those.
– Could it just be some routine agency report, monitoring an ongoing process, — people may just accept it as okay, no special action needed, or decide that something should be done to improve its function?
– Yes, the process could start with any of those. Can we call it a ‘case’, as a catchall label, for now? But whatever the label, there needs to be a forum, a place, a medium to alert people that there is a candidate case for starting the process. A ‘potential case candidate listing’, for information. Anybody who feels there is a need to do something could post such a potential case. It may be something a regular agency is already working on or should address by law or custom. But as soon as somebody else picks it up as something out of the ordinary, significant enough to warrant a public discussion, the system will ‘open’ the case, which means establishing a forum corner, a venue or ‘site’ for its discussion, and invite public contributions to that discussion.
– Yeah, and it will get swamped immediately with all kinds of silly and irrelevant posts. How does the system deal with that? Trolls, blowhards, just people out to throw sticks into the wheels?
– Good question. The problem is how to sort out the irrelevant stuff — but who is to decide what’s what? And throw out what’s irrelevant?
– Yes, that itself could lead to irrelevant and distracting quarrels. I think it’s necessary to have a first file where everything is kept in its original form, a ‘Verbatim’ depository, for reference. And deal with the decision about what’s relevant by other means, for example the process of assessment of the merit of contributions. First, everybody who makes a contribution will get a kind of ‘basic contribution credit point’, a kind of ‘present’ score, which is initially just ‘empty’. If it’s the first item of some significance for the discussion, it will get filled with an adjustable but still neutral score — mere repetitions will stay ‘noted’ but empty.
– Good idea! This will be an incentive to make significant information fast, and keep people from filling the system with the same stuff over and over.
– Yes. But then you need some sorting out of all that material, won’t you?
– True. You might consider that as part of an analysis service, determining whether a post contains claims that are ‘pertinent’ to the case. It may just consist of matching a term — of a ‘topic’ or subject, that’s part of the initial case description, or provides a link to any subsequent contribution already posted. Each term or topic is now listed as the content subject of a number of possible questions or issues — the ‘potential issue family’ of factual, explanatory, instrumental, and deontic (ought-) questions that can be raised about the concept. This can be done according to the standard structure of an IBIS (issue based information system), a ‘structured’ or formalized file that consists of the specific questions and the respective answers and arguments to those. Of course somebody or something must be doing this — an ‘Analysis’ or ‘Formalizing’ component — either some human staff, or an automated system which needs to be developed. Ideally, the participants will learn to do this structuring or formalizing themselves, to make sure the formalized version expresses their real intent.
– And that ‘structured’ file will be accessible to everybody, as well as the ‘verbatim’ file?
– Yes. Both should be publicly accessible as a matter of principle. But access ‘in principle’ is not yet very useful. Such files aren’t very informative or interesting to use. Most importantly, they don’t provide the overview of the discussion and of the relationship between the issues. This is where the provision and rapid updating of discourse maps becomes important. There should be maps of different levels of detail: topic maps, just showing the general topics and their relationships, issue maps that provide the connections between the issues, and argument maps that show the answers or arguments for a specific issue, with the individual premises and their connections to the issues raised by each premise.
– So what do we have now: a support system with several storage and display files, and the service components to shuffle and sort the material into the proper slots. Al, I see did you draw a little diagram there?
– Yes – I have to doodle all this in visual form to understand it:

Figure 1 — The main discourse support system: basic content components
– Looks about right, for a start. You agree, Sophie?
– Yes, but it doesn’t look that much different from the argumentative or IBIS type system we know and started from. What happened to the concern about the adversarial flavor of this kind of system? Weren’t we trying to defuse that? But how? Get rid of arguments?
– Well, I don’t think you can prevent people from entering arguments — pros and cons about proposed plans or claims. Every plan has ‘pros’ – the benefits or desirable results it tries to produce – and ‘cons’, its costs, and any undesirable side-and after-effects. And I don’t think anybody can seriously deny that they must be brought up, to be considered and discussed. So they must be acknowledged and accommodated, don’t you think?
– Yes. And the evaluation of pro and con merit of plan proposals, based on the approach we’ve been able to develop so far, will depend on establishing some argument plausibility and argument weight.
– I agree. But isn’t there a way in which the adversarial flavor can be diminished, defused?
– Lets’ see. I think there are several ways that can be done. First, in the way the material is presented. For example, the basic topic maps don’t show content as adversarial, and the issue maps can de-emphasize the underlying pro-and con partisanship, if any, by the way the issues are phrased. Whether argument maps should be shown with complete pro and con arguments, is a matter of discussion, perhaps best dealt with in each specific case by the participants. This applies most importantly to the way the entire discourse is framed, and the ‘system’ could suggest forms of framing that avoid the expectation of an adversarial win-lose outcome. If a plan is introduced as a ‘take-it-or-leave-it’ proposal to be approved or rejected, inevitably some participants can see themselves as the intended or unintended losing party, which generates the adversarial attitudes. Instead, if the discourse is started as an invitation to contribute to the generation of a plan that avoids placing the costs or disadvantages unfairly on some affected folks, and the process explicitly includes the expectation of plan modification and improvement, that attitude will be different.
– So the participants in this kind of process will have to get some kind of manual of proper or suggested behavior, is that right? How to express their ideas?
– I guess that would helpful. Suggestions, yes, not rules, if possible.
– Also, if I understand the evaluation ideas right, the reward system for contributions can include giving people points for information items that aren’t clearly supporting one party or the other, so individual participants can ‘gain’ by offering information that might benefit ‘the other’ party, would that help to generate a more cooperative attitude?
– Good point. Before we get to the evaluation part though, there is another aspect — one of the ‘approach shortcomings’, that I think we need to address.
– Right, I’ve been waiting for that: the systems modeling question. How to represent complex relationships of systems models in the displays presented to the participants? Is that what you are referring to?
– Yes indeed.
– So do you have any suggestions for that? It seems that it is so difficult — or so far off the argumentative planners’ radar – that it hasn’t been discussed or even acknowledged let alone solved yet?
– Sure, it almost looks like a kind of blind spot. I think there are two ways this might, or should be, dealt with. One is that the system’s research component — here I mean the discourse support system — can have a service that make searches in the appropriate data bases to find and enter information about similar cases, where systems models may have been developed, and enter the systems descriptions, equations and diagrams — most importantly, the diagrams — to the structured file and the map displays. In the structured file, questions about the model assumptions and data can then be added — this was the element that is usually missing in systems diagrams. But the diagrams themselves do offer a different and important way for participants to gain the needed overview of the problem they are dealing with.
– So far, so good. Usually, the argumentative discussion and the systems are speaking different languages, have different perspectives, with different vocabularies. What can we do about that?
– I was coming to that — it was the second way I mentioned. But the first step, remember, is that the systems diagrams are now becoming part of the discussion, and any different vocabulary can be questioned and clarified together with the assumptions of the model. That’s looking at it from the systems side. The other entry, from the argumentative side, can be seen when we take a closer look at specific arguments. The typical planning argument is usually only stated incompletely — just like other arguments. It leaves out premises the arguer feels can be ‘taken for granted’. A more completely stated planning argument would spell out these three premises of the ‘conclusion-claim’, that
‘Proposal or Plan P should be adopted,
because
P will lead to consequence or result R , (given conditions C)
and
Result R ought to be pursued
(and
conditions C are present)’.
The premise in parenthesis, about conditions C, is the one that’s most often not spelled out, or just swept under the rug with phrases such as ‘all else being equal’. But take a closer look at that premise. Those conditions — the ones under which the relationship between P and R can be expected to hold or come true — refer to the set of variables we might see in a systems diagram, interacting in a number of relationship loops. It’s the loops that make the set a true system, in the minds of the systems thinkers.
– Okay, so what?
– What this suggests is, again, a twofold recommendation, that the ‘system’ (the discourse system) should offer as nudges or suggestions for the participants to explore.
– Not rules, I hope?
– No: suggestions and incentives. The first is to use existing or proposed system diagrams as possible sources for aspects — or argument premises — to study and include in the set of concerns that should be given ‘due consideration’ in a decision about the case. In other words, turn them into arguments. Of the defused kind, Sophie. The second ‘nudge’ is that the concerns expressed in the arguments or questions by people affected by the problem at hand, or by proposed solutions — should be used as material for the very construction of the model of problem situation by the system modeler for the case at hand.
– Right. For the folks who are constructing systems models for the case at hand.
– Yes, That would likely be part of the support system service, but there might be other participants getting involved in it too.
– I see: Reminders: as in ‘do you think this premise refers to a variable that should be entered into the systems model?’
– Good suggestion. This means that the construction of the system model is a process accompanying the discourse. One cannot precede the other without remaining incomplete. It also requires a constant ‘service’ of translation between any disciplinary jargon of the systems model — the ‘systems’ vocabulary as well as the special vocabulary of the discipline within which the system studied is located. And of course, translation between different natural languages, as needed. For now, let’s assume that would be one of the tasks of the ‘sorting’ department; we should have mentioned that earlier.
– Oh boy. All this could complicate things in that discourse.
– Sure — but only to the extent that there are concepts that need to be translated, and aspects that are significantly different as seen from ordinary ‘argumentative’ or ‘parliamentary’ planning discussion perspective as opposed to a systems perspective, don’t you agree?
– So let’s see: now we have some additional components in your discourse support system: the argument analysis component, the systems modeling component, the different translation desks, and the mapping and display component. What’s next?
– That would be the evaluation function. From what we know about evaluation, in this case evaluating the merit of discussion contributions, the process of clarifying, testing, improving our initial offhand judgments about things to more solidly well-founded, deliberated judgments requires that we make the deliberated overall judgments a function, that is, dependent on, the many ‘partial’ judgments provided in the discussion and in the models. And we have talked about the need for a better connection between the discourse contribution merit and the decision judgment. This is the purpose of the discourse, after all, right?
– Yes. And the reason we think there needs to be a distinct ‘evaluation’ step or function is that quite often, the link between the merit of discussion contributions and the decision is too weak, perhaps short-circuited, prejudiced, or influenced by ‘hidden agenda’ — improper, illicit agenda considerations, and needs to be more systematic and transparent. In other words, the decisions should be more ‘accountable’.
– That’s quite a project. Especially the ‘accountability’ part — perhaps we should keep that one separate to begin with? Let’s just start with the transparency aspect?
– Hmm. You don’t seem too optimistic about accountability? But without that, what use is transparency? If decision makers, whoever they might be in a specific case, don’t have to be accountable for their decision, does it matter how transparent they are? But okay, let’s take it one item at a time.
– Seems prudent and practical. Can you provide some detail about that evaluation process?
– Let me see. We ask the participants in the process to express their judgments about various concepts in the process, on some agreed-upon scale. The evaluation process of our friend suggests a plausibility scale. It applies to judgments about how certain we are that a claim is true, or how probable it is — or how plausible it is — if neither truth nor probability really apply, as in ought-claims. It ranges from some positive number to a negative point, agreed to mean ‘couldn’t be more plausible’ or ‘couldn’t be less plausible’, respectively, with a midpoint of zero expressing ‘don’t know’, ‘can’t judge’.
– What about those ‘ought’ claims in the planning argument? ‘Just ‘plausible’ doesn’t really express the ‘weighing’ aspect we are talking about?
– Right: for ought-claims — goals, objectives — there must be a preference ranking or a scale expressing weight of relative importance. The evaluation ‘service’ system component will prepare some kind of form or instrument people can use to express and enter those judgments. This is an important step where I think the adversarial factor can be defused to some extent: if argument premises are presented for evaluation individually, not as part of the arguments in which they may have been entered originally, and without showing who was the original author of a claim, can we expect people to evaluate them more according to their intrinsic merit and evidence support, and less according to how they bolster this or that adversarial party?
– I’d say it would require some experiments to find out.
– Okay: put that on the agenda for next steps.
– Can you explain how the evaluation process would continue?
– Sure. First let me say that the process should ideally include assessment during all phases of the process. If there is a proposal for a plan or a plan detail, for example, participants should assign a first ‘offhand’ overall plausibility score to it. That score scan then be compared to the final ‘deliberated’ judgment, as an indicator of how the discussion has achieved a more informed judgment, and what difference that made. Now, for the details of the process. To get an overall deliberated plausibility judgment, people only need to provide plausibility scores and importance weights for the individual premises of the pro and con planning arguments. For each individual participant, the ‘system’ can now calculate the argument plausibility and the argument weight of each argument, based on the weight the person has assigned to its deontic premise, and the person’s deliberated proposal plausibility, as a function of all the argument weights.
– I seem to remember that there were some questions about how all those judgments should be assembled and aggregated into the next deliberated value?
– Yes, there should be some more discussion and experiments about that. But I think those are mostly technical details that are solved in principle, and can be decided upon by the participants to fit the case.
– And the results are then posted or displayed to the group for review?
– Yes. This may lead to more questions and discussion, of course, or for requests for more research and discussion, if there are claims that don’t seem to have enough support to make reasonable assessments, or for which the evidence is disputed. I see you are getting worried, Sophie: will this go on forever? There’s a kind of stopping rule: when there are no more questions or arguments, the process can stop and proceed to the decision phase.
– I think the old parliamentary tradition of ‘calling the question’ when the talking has gone on for too long should be kept in this system.
– Sure, but remember, that one was needed mainly because there was no other filter for endless repetition of the same points wrapped in different rhetoric. The rule of adding the same point only once into the set of claims to be evaluated will put a damper on that, don’t you think?
– So Al, did you add the evaluation steps to your diagram?
– Yes. Here’s what it looks like now:

Figure 2 — The discourse support system with added evaluation components
– Here is another suggestion we might want to test, and add to the picture – coming back to the idea of the reward system helping to reduce the adversarial aspect: We now have some real measures — not only for the individual claims or information items that make up the answers and arguments to questions, but also for the plausibility of plan proposals that are derived from those judgments. So we can use those as part of a reward mechanism to get participants more interested in working out a final solution and decision that is more acceptable to all parties, not just to ‘win’ advantages for their ‘own side’.
– You have to explain that, Bog-Hubert.
– Sure. Remember the contribution credit points that were given to everybody, for making a contribution, to encourage participation? Okay: in the process of plausibility and importance assessment we were asking people to do, to deliberate their own judgments more carefully, they were assessing the plausibility and weight of relative importance of those contributions, weren’t they? So if we now take some meaningful group statistic of those assessments, we can modify those initial credits by the value or merit the entire group was assigning to a given item.
– ‘Meaningful’ statistic? What are you saying here? You mean, not just the average or weighted average?
– No, some indicator that also takes account of the degree of support presented for a claim, and the degree of agreement or disagreement in the group. The needs to be discussed. In this way, participants will build up their ‘contribution merit credit account’. You could then also earn merit credits for information that –from a narrow partisan point of view — would be part of an argument for ‘the other side’ — credit for information that serves the whole group.
– Ha! now I understand what you said initially about the evaluation function also serving to reduce the amount of trivial, untrue, and plain irrelevant stuff people might post in such discussions: if their information is judged negatively on the plausibility scale, that will reduce their credit accounts. A way to reward good information that can be well supported, and discourages BS and false information… I like that.
– Good. In addition to that, people could also get credit points for the quality of the final solution — assuming that the discourse includes efforts to modify initial proposals some people find troublesome, to become more acceptable — more ‘plausible’ — to all parties. And the credit you earn may be in part determined by your own contribution to that result. So there are some possibilities for such a system to encourage more constructive cooperation.
– Sounds good. As you said, we should try to do some research to see whether this would work, and how the reward system should be calibrated.
– So the reward mechanism adds another couple of components to your diagram, Al?
– Yes. Bog-hubert said that the evaluation process should really be going on throughout the entire process, so the diagram that shows it just after the main evaluation of the plan is completed is a little misleading. I tried to keep it simple. And there’s really just one component that will have to keep track of the different steps:

Figure 3 –The process with added contribution reward component
– Looks good, thanks, Al. But what I don’t see there yet is how it connects with the final decision. I think you got derailed from finishing your explanation of the evaluation process, Bog-Hubert?
– Huh? What did I miss?
– You explained how each participant got a deliberated proposal plausibility score. Presumably one that’s expressed on the same plausibility scale as the initial premise plausibility judgments, so we can understand what the number means. Okay. Then what? How do you get from that to a common decision by the entire community of participants?
– You are right; I didn’t get to that. Well…
– Why doesn’t the system calculate an overall group proposal plausibility score from the individual scores?
– I guess there are some problems with that step, Vodçek. If you mean something like the average plausibility score. Are you saying that it should be the deciding criterion?
– Well… why not? It’s like all those opinion polls, only better, isn’t it? And definitely better that just voting?
– No, friends, I don’t think the judgment about the final decision should not be ‘usurped’ by such a score. For one, unless there are several proposals that have all been evaluated in this way so you could say ‘pick the one with the highest group plausibility score’, you’d have to agree on a kind of threshold plausibility a solution would have to achieve to get accepted. And that would just be another controversial issue. Also, a simple group average could gloss over, hide serious differences of opinion. And like majority voting, just override the concerns of minority groups. So such statistics should always be accompanied by measures of the degree of consensus and disagreement, at the very least.
– Couldn’t there be a rule that a proposal is acceptable if all the individual final plan plausibility scores are better than the existing problem situation? Ideally, of course, all on the positive side of the plausibility scale, but in a pinch at least better than before?
– That’s another subject for research and experiments, and agreements in each situation. But in reality, decisions are made according to established (e.g. constitutional) rules and conventions, habits or ad hoc agreements. Sure, the discourse support systems could provide some useful suggestions or advice to the decision-makers, based on the analysis of the evaluation results. A ‘decision support component’. One kind of advice might be to delay decision if the overall plausibility for a proposal is too close to the midpoint (‘zero’) value of the plausibility scale — indicating the need for more discussion, more research, or more modification and improvement. Similarly, if there is too much disagreement in the overall assessment – if a group of participants show very different results from the majority, even if the overall ‘average’ result looks like there is sufficient support, the suggestion may be to look at the reasons for the disagreement before adopting a solution. Back to the drawing board…
– Getting back to the accountability aspect you promised to discuss: Now I see how that may be using the evaluation results and credit accounts somehow — but can you elaborate how that would work?
– Yes, that’s a suggestion thrown around by Abbé Boulah some time ago. It uses the credit point account idea as a basis of qualification for decision-making positions, and the credit points as a form of ‘ante’ or performance bond for making a decision. There are decisions that must be made without a lot of public discourse, and people in those positions ‘pay’ for the right to make decisions with an appropriate amount of credit points. If the decision works out, they earn the credits back, or more. If not, they lose them. Of course, important decisions may require more points than any individual has compiled; so others can transfer some of their credits to the person, unrestricted, or dedicated for specific decisions. So they have a stake, — their own credit account — and lose their credits if they make or support poor decisions. This also applies to decisions made by bodies of representatives: they too must put up the bond for a decision, and the size of that bond may be larger if the plausibility evaluations by discourse participants show significant differences, that is, disagreements. They take a larger risk to make decisions about which some people have significant doubts. But I’m sorry, this is getting away from the discussion here, about the discourse support system.
– Another interesting idea that needs some research and experiments before the kinks are worked out.
– Certainly, like many other components of the proposed system — proposed for discussion. But a discussion that is very much needed, don’t you agree? Al, do you have the complete system diagram for us now?
– So far, what I have is this — for discussion:
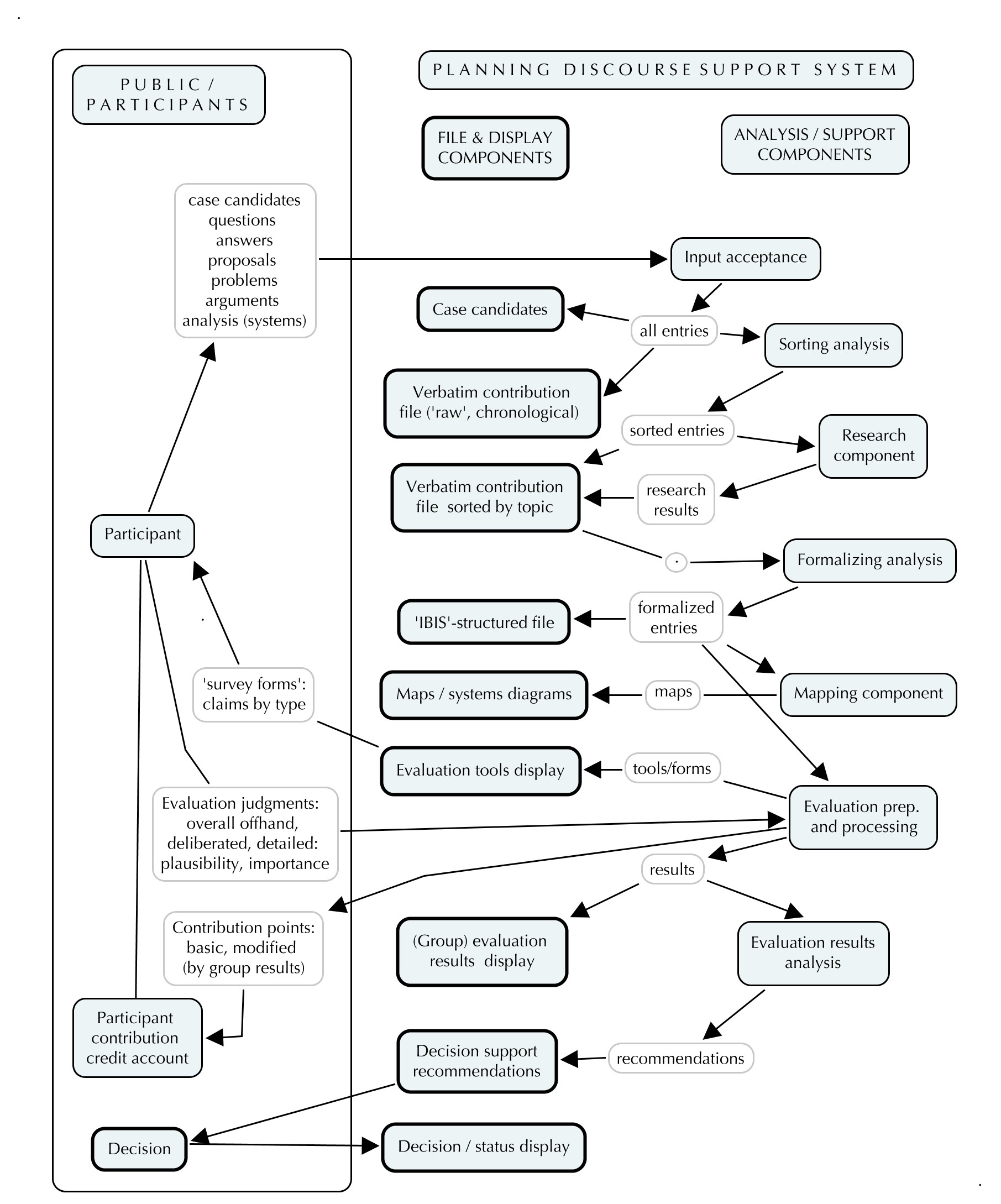
Figure 4 — The Planning Discourse Support System – Components
– So, Bog-Hubert: should we make a brief list of the research and experiments that should be done before such a system can be applied in practice?
– Aren’t the main parts already sufficiently clear so that experimental application for small projects could be done with what we have now?
– I think so, Vodçek — but only for small projects with a small number of participants and for problems that don’t have a huge amount of published literature that would have to be brought in.
– Why is that, Bog-Hubert?
– See, Sophie: the various steps have been worked through and described to explain the concept, but it had to be done with different common, simple software programs that are not integrated: the content from one component in Al’s diagram have to be transferred ‘by hand’ from one component to the next. For a small project, that can be done with a small support staff with a little training. And that may be sufficient to do a few of the experiments we mentioned to fine-tune the details of the system. But for larger projects, what we’d need is a well-integrated software program that could do most of the transferring work from one component to the next ‘automatically’.
– Including creating and updating the maps?
– Ideally, yes. And I haven’t seen any programs on the market that can do that yet. So that should the biggest and top priority item on the research ‘to do’ list. Do you remember the other items we should mention there?
– Well, there were a lot of items you guys mentioned in passing without going into much detail – I don’t know if that was because any questions about those aspects had been worked out already, or because you didn’t have good answers for them? For example, the idea of building ‘nudging’ suggestions into the system to encourage participants to put their comments and questions into a form that encourages cooperation and discourages adversarial attitudes?
– True, that whole issue should be looked into more closely.
– What about the issue of ‘aggregation functions’ – wasn’t that what you called them? They way participants’ plausibility and importance judgments about individual premises of arguments, for example, get assembled into argument plausibility, argument weights, and proposal plausibility?
– Not to forget the problem of getting a reasonable measure of group assessment from all those individual judgment scores.
– Right. It may not end up being a multivariable one, not just a single measure. Like the weather, we need several variables to describe it.
– Then there is the whole idea of those merit points. It sounds intriguing, and the suggestion to link them to the group’s plausibility assessments makes sense, but I guess there are a lot of details to be worked out before it can be used for real problems.
– You say ‘real problems’ – I guess you are referring to the way they could be used in a kind of game, just like the one we ran here in the Tavern last year about the bus system, where the points are just part of the game rules, as opposed to real cases. I think the detailed development of this kind of game should be on the list too, since games may be an important tool to make people familiar with the whole approach. How to get these ideas out there may take some thinking too, and several different tools. But using these ideas for real cases is a whole different ball game, I agree. Work to do.
– And what about the link between all those measures of merit of people’s information and arguments and the final decision. Isn’t that going to need some more work as well? Or will it be sufficient to just have the system sound an alarm if there is too much of a discrepancy between the evaluation results and, say, a final vote?
– We’ll have to find out – as we said, run some experiments. Finally, to come back to our original problem of trying to reduce the adversarial flavor of such a discourse: I’d like to see some more detail about the suggestion of using the merit point system to encourage and reward cooperative behavior. Linking the individual merit points to the overall quality of the final decision — the plan the group is ending up adopting — sounds like another good idea that needs more thought and specifics.
– I agree. And this may sound like going way out of our original discussion: we may end up finding that the decision methods themselves may need some rethinking. I know we said to leave this alone, accept the conventional, constitutional decision modes just because people are used to them. But don’t we agree that simple majority voting is not the ultimate democratic tool it is often held out to be, but a crutch, a discussion shortcut, because we don’t have anything better? Well, if we have the opportunity to develop something better, shouldn’t it be part of the project to look at what it could be?
– Okay, okay, we’ll put it on the list. Even though it may end up making the list a black list of heresy against the majesty of the noble idea of democracy.
– Now there’s a multidimensional mix of metaphors for you. Well, here’s the job list for this mission; I hope it’s not an impossible one:
– Developing the integrated software for the platform
– Developing better display and mapping tools, linked to the formalized record (IBIS)
– Developing ‘nudge’ phrasing suggestions for questions and arguments that minimize adversarial potential
– Clarifying questions about aggregation functions in the evaluation component
– Improving the linkage between evaluation results (e.g. argument merit) and decision
– Clarifying, elaborating the discourse merit point system
– Adding improvement / modification options for the entire system
– Developing alternative decision modes using the contribution merit evaluation results.
– That’s enough for today, Bog-Hubert. Will you run it by Abbé Boulah to see what he thinks about it?
– Yeah, he’ll just take it out to Rigatopia and have them work it all out there. Cheers.
—

Sorry for the long wait for a reply — WordPress used to notify me of comments to moderate but doesn’t do so anymore. There are a number of articles on related topics on Academia.edu. My book- just out recently, ‘Rigatopia’ deals with similar issues (among other things) in a ‘Tavern discussion’ format.
Thanks for the comment — this is a work in progress and I appreciate any help I can get.
Thanks for the comment. Are you working on similar issues? If so, I’d appreciate any helpul hints.