An effort to clarify the role of deliberative evaluation in the planning and policy-making process. Thorbjørn Mann, January 2020. (Draft)
PROCEDURE EXAMPLE 2:
EVALUATION OF PLANNING ARGUMENTS (PROS & CONS)

Argument evaluation in the planning discourse
Planning, like design, can be seen as an argumentative process (Rittel): Ideas and proposals are generated, questions are raised about them. The typical planning issues — especially the ‘deontic’ (ought-) questions about what the plan ought to be and how it can be achieved — generate not only answers but arguments — the proverbial ‘pros and cons’ . The information needed to make meaningful decisions — based on ‘due consideration’ of all concerns by all parties affected by the problem the plan is aiming to remedy, as well as by any solution proposals, is often coming mainly via those pros and cons. Taking this view seriously, it becomes necessary to address the question of how those arguments should be evaluated or‘weighed’ . After all, those arguments are supporting contradictory conclusions (claims), so just ‘considering. is not quite enough.
Argumentation as a cooperative rather than adversarial interaction
The very concept of the‘argumentative view of planning is somewhat controversial because many people misunderstand ‘argument’ itself as a nasty adversarial, combative, uncooperative phenomenon, a ‘quarrel’ . (I have suggested the label ‘quarrgument’ for this). But ‘argument’ is originally understood as a set of claims (premises) that together support another claim, the ‘conclusion. For planning, arguments are items of reasoning that explore the ‘pros and cons about plans; and an important underlying assumption is that we ‘argue’ — exchange arguments with others because we believe that the other will accept or consider the position about the plan we are talking about because the other already believes or accepts the premises we offer, — or will do so once we offer the additional support we have for them. It is unfortunate that even recent research on computer-assisted argumentation seems to be stuck in the ‘adversarial’ view of arguments, seeing arguments as ‘attacks’ on opposing positions rather than a cooperative search for a good planning response to problems or visions for a better future.
‘Planning arguments’
There is another critical difference between the arguments discussed in traditional logic textbooks and and the kinds I call ‘planning arguments: The traditional argumentation concern was to establish the truth or falsity of claims about the world, and that the discussion — the assessment of arguments — will ‘settle’ that question in favor of one or the other. This does not apply to planning arguments: The planning decision does not rest on single ‘clinching’ arguments but on the assessment of the entire set of pros and cons. There are always real expected benefits and real expected costs, and as the proverbial saying has it, they must be ‘weighed’ against one another to lead to a decision. There has not been much concern about how that ‘weighing’ can or should be done, and how that process might lead to a reasoned judgment about whether to accept or reject a proposed plan. I have tried to develop a way to do this — a way to explain what our judgments are based on — beginning with an examination of the structure of ‘planning arguments.
The structure of planning arguments and their different types of premises
I suggest that planning arguments can be represented in a following general ‘standard planning argument’ form, the simplest version being the following ‘pro’ argument pattern:
Proposal ‘ought’ claim (‘conclusion’): Proposal PLAN A ought to be adopted
because
1. Factual-instrumental premise: Implementing PLAN A will lead to outcome B
given conditions C
and
2. Deontic premise: Outcome B ought to be pursued;
and
3. Factual premise: Conditions C are (or will be) given.
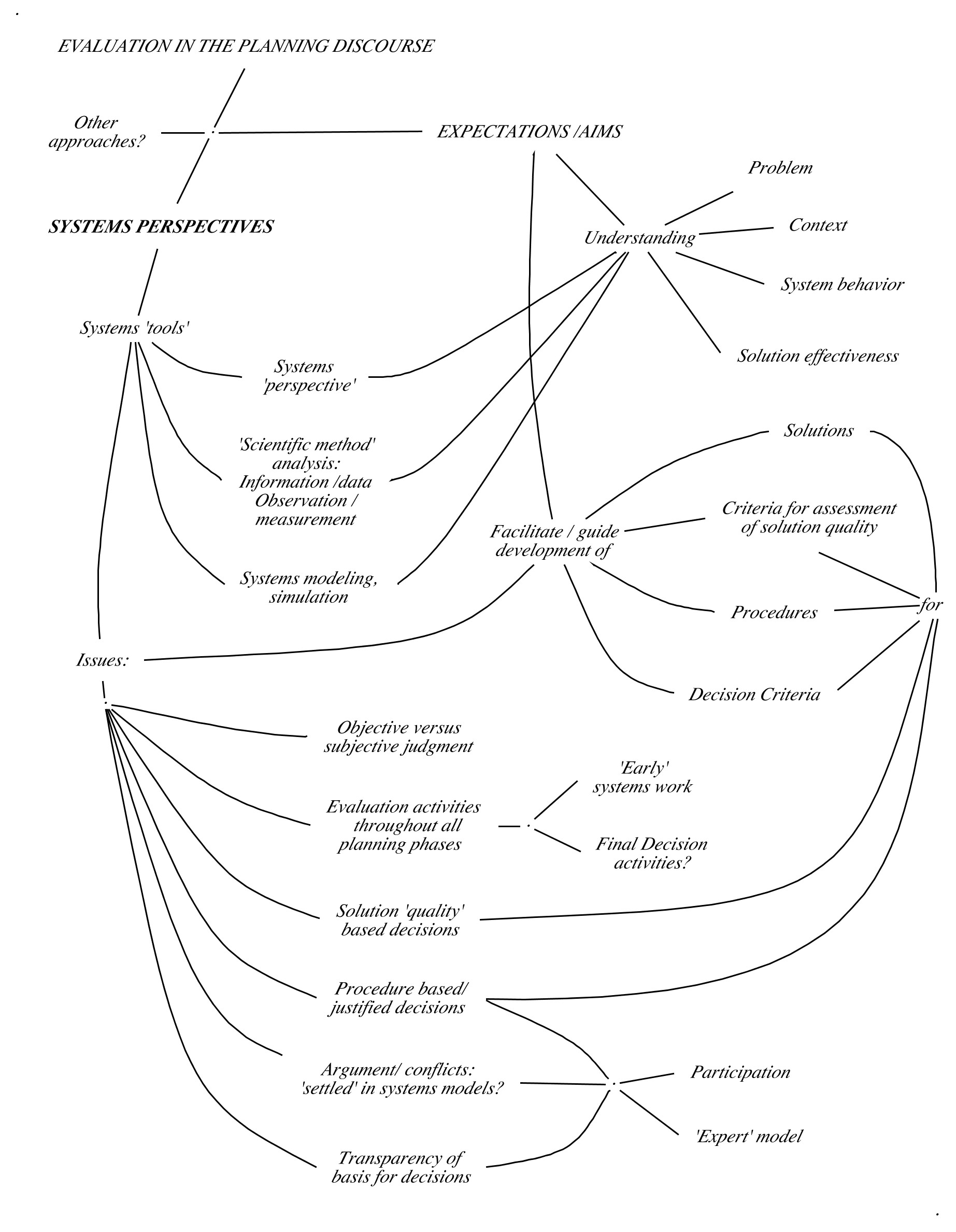
This form is not conclusively ‘valid’ in the formal logic sense, according to which it is considered ‘inconclusive’ and ‘defeasible’. There are usually many such pros and cons supporting or questioning a proposal: no single argument (other that evidence pointing out flaws of logical inconsistency or lacking feasibility, leading to rejection) will be sufficient to make a decision. Any evaluation of planning arguments therefore must be embedded in a ‘multi-criteria’ analysis and aggregation of judgments into the overall decision.
It will become evident that all the judgments people make will be personal ‘subjective’ judgments, not only about the deontic (ought) premise but even about the validity and salience of the ‘factual’ premises: they are all about estimated about the future — not yet validated by observation and measurement.
The judgment types of planning argument premises:
‘plausibility’ and weight of importance
There are two kinds of judgments that will be needed. The first is an assessment of the ‘plausibility’ of each claim. The term ‘plausibility’ here includes the familiar‘truth’ (or degree of certainty or probability about the truth of a claim, and the advisability, acceptability, desirability of the deontic claim. It can be expressed as a judgment on a scale e.g. of -1 to +1, with ‘-1’ meaning complete implausibility to +1 expressing ‘total plausibility’, virtual certainty, and the center point of zero meaning ‘don’t know, can’t judge’ . The second one is a judgment about the ‘weight’ of relative importance‘ of the ‘ought’ aspect. It can be expressed e.g. by a score between zero meaning (totally unimportant) and +1 meaning ‘totally important’, overriding all other aspects; the sum of all the weights of deontic premises must be equal to +1.
Argument plausibility
The first step would be the assessment of plausibility of the entire single argument, which would be a function of all three premise plausibility scores to result in an ‘Argument plausibility’ score.
For example, an argument i with pl(1) =0.5, pl(2) = 0.8, and pl(3) = 0.9 might get an argument plausibility : Argpl (i) of 0.5 x 0.8 x 0.9 = 0.36.
Argument weight of relative importance
The second step would be to assess the ‘argument weight’ of each argument, which can be done by multiplying the weight of relative importance of its deontic premise (premise 2 in the pattern above) with the argument plausibility: Argw(i) = Argpl(i) x w(i).
That weight will again be a value between zero (meaning ‘totally unimportant’) and +1 (meaning ‘all-important’ i.e. overriding all other considerations). This should be the result of the establishment of a ‘tree’ of deontic concerns (similar to the ‘aspects’ of the ‘Formal evaluation’ procedure in procedure example 1) that gives each deontic claim its proper place as a main aspect, sub-aspect, sub-sub-aspect or ‘criterion’ in the aspect tree, and assigning weights between 0 and 1 such that these add up to 1, at each level.
A deontic claim located at the second level of the aspect tree, having been assigned a weight of .8 at that level, being a sub-aspect to an aspect at the first level with a weight of +.4 at that level, would have a premise weight of w = 0.8 x 0.4 = 0.32. The argument weight with a plausibility of 0.36 would be Argw(i) = 0.36 x 0.32 = 0.1152 (rounded up as 0.12).
Plan plausibility
All the argument weights could the be aggregated to the overall ‘plan plausibility’ score, for example by adding up all argument weights:
Planpl = ∑ Argw(i) for all argument weights i (of an individual participant)
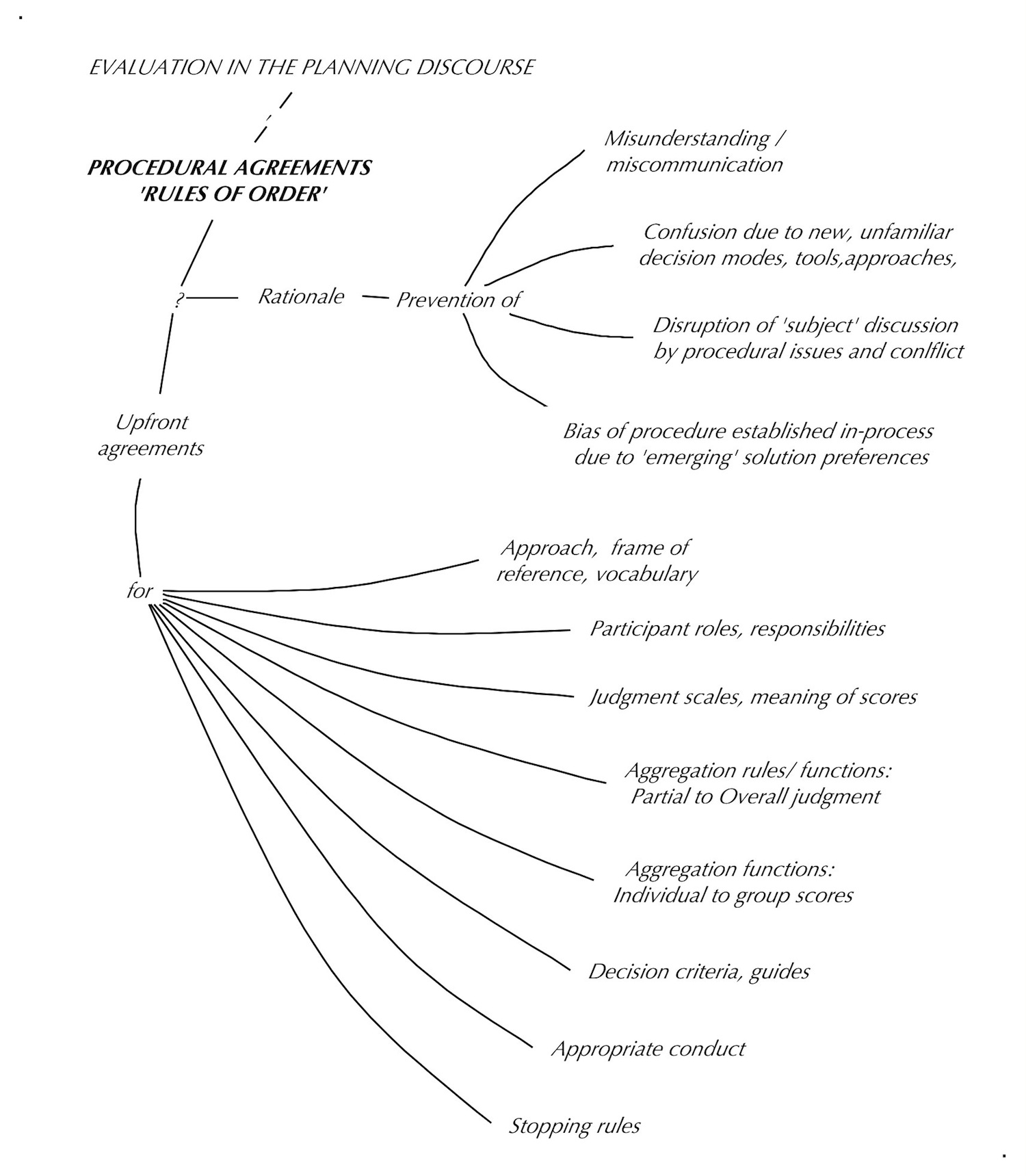
Of course, there are other possible aggregation forms. (See the sections on ‘Aggregation’ and ‘Decision Criteria). Which one of those should be used in any specific case must be specified — agreed upon — in the ‘procedural agreements’ governing each planning project.
It should be noted that in a worksheet simply listing all arguments with their premises for plausibility and weigh assignments, there is no need for identifying arguments as ‘pro’ and ‘con’, as intended by their respective authors. Any argument given a negative premise plausibility by a participant will automatically end up getting a negative argument weight and thus becoming a ‘con’ argument for that participant — even if the argument was intended by its author as a ‘pro’ argument. This makes it obvious that all such assessments are individual, subjective judgments, even if the factual and factual-instrumental premises of arguments are considered ‘objective-fact’ matters.
The process of evaluation of planning arguments within the overall discourse
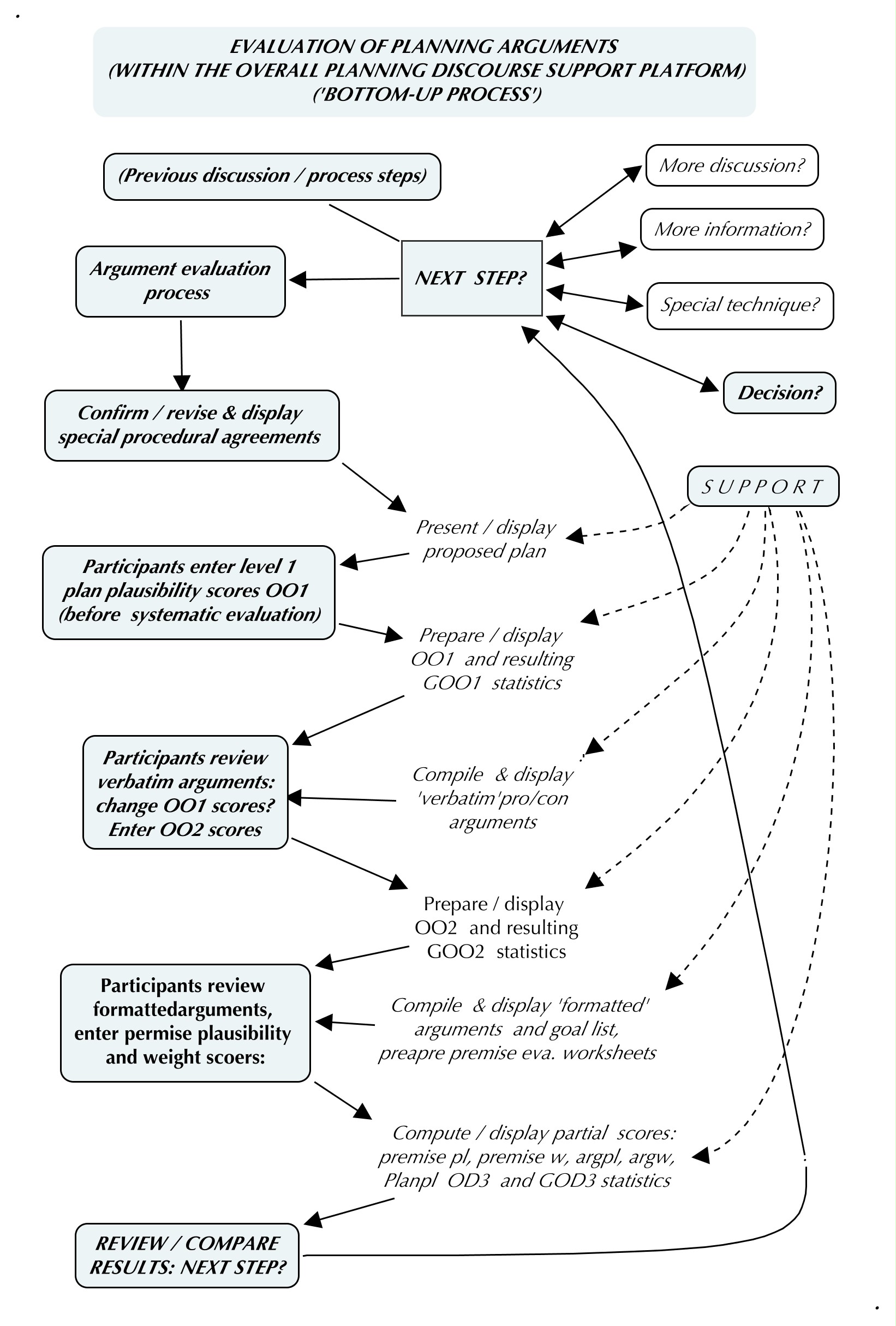
The diagram below shows the argument assessment process as it will be embedded in an overall discourse. Its central feature is the ‘Next Step?’ decision, invoked after each major activity. It lets the participants in the effort decide — according to rules specified in those procedural agreements — how deeply into the deliberation process they wish to proceed: they could decide to go ahead with a decision after the first set of overall offhand judgments, skipping the detailed premise analysis and evaluation if they feel sufficiently certain about the plan.

Process of argument assessment within the overall discourse
The use of overall plan plausibility scores:
Group statistics of the set of individual plan plausibility scores.
It may be tempting to use the overall plan plausibility scores directly as decision guides or determinants. For example, to determine a statistic such as the average of all individual scores Planpl(j) for the participants j in the assessment group, as an overall ‘group plausibility score‘ GPlanpl, e.g. GPlanpl = 1/n ∑ Planpl(j) for all n members of the panel.
And in evaluating a set of competing plan alternatives: to select the proposal with the highest ‘group plausibility’ score.
Such temptations should be resisted, for a number of reasons, such as: whether a discussion has succeeded in bringing in all pertinent items that should be given ‘due consideration’; the concern that planning arguments tend to be of ‘qualitative’ nature and often don’t easily address quantitative measures of performance; questions regarding principles, the time frame of expected plan effects and consequences; whether and how issues of ‘quality’ of a plan are adequately addressed in the form of arguments; and the question of the appropriate ‘social aggregation’ criterion to be applied to the problem and plan in question: many open questions:
Open questions
Likely incompleteness of the discussion
It is argued that participation of all affected parties and a live discussion will be more likely to bring our the concerns people are actually worried about, than e.g. reliance on general textbook knowledge by panels or surveys made up by experts who ‘don’t live there’. But even the assumption that the discussion guarantees complete coverage is unwarranted. For example, is somebody likely to consider raising an issue about a plan feature that they know will affect another party negatively (when they expect the plan to be good for the own faction) — if the other party isn’t aware enough about this effect, and does not raise it? Likewise; some things may be expected to be so much matters ‘of course’ that nobody considers it necessary to mention it. So unless the overall process includes several different means of getting such information — systems modeling, simulation, extensive scrutiny of other cases etc. — the argumentative discussion alone can’t be assumed to be sufficient to bring up all needed information.
Quantitative aspects in arguments.
The typical planning argument will usually be framed in more ‘qualitative’ terms than quantitative measures. For example: in an argument that “The plan will be more sustainable’ than the current situation” this matters in the plausibility assessment: It can be seen as quite plausible as long as there is some evidence of sustainability improvement, so participants may be inclined to give it a high pl-score close to +1. By comparison, if somebody instead makes the same argument but now claims a specific ‘sustainability’ performance measure — one that others may consider as too optimistic, and therefore assign it a plausibility score closer to zero or even slightly negative: how will that affect the overall assessment? What procedural provisions would be necessary to needed to adequately deal with this question?
The issue of ‘quality’ or ‘goodness’ of a proposed solution.
It is of course possible that a discussion examines the quality or ‘goodness’ of a plan in detail, but as mentioned above, this will likely also be in general, qualitative terms, and often even avoided because to the general acceptance of sayings like’ you can’t argue about beauty’ , so the discussion will have some difficulty in this respect, if it does mention beauty at all, or spiritual value, or the appropriateness of the resulting image. Likewise, requirements for the implementation of the plan, such as meeting regulations, may not be discussed.
The decreasing plausibility ‘paradox’
Arguably, all ‘systematic’ reasoning efforts, including discussion and debate, aim a giving decision-makers a higher degree of certainty about their final judgment, than, say, just fast offhand intuitive decisions. However, it turns out that the more depth as well as breadth of discussion is done, the more final plausibility judgment scores will tend to end up closer to the ‘zero’ or ‘don’t know’ plausibility — if the plausibility assessment is done honestly and seriously, and the aggregation method suggested above is used: Multiplying the plausibility assessments for the various premises (which for the factual premises will be probability estimates). These judgments being all about future expectations, they cannot honestly be given +1 (‘total certainty’) scores or even scores close to it, the less so, the farther out in the future the effects are projected. This result can be quite disturbing and even disappointing to many participants, when final scores are compared with initial ‘offhand’ judgments.
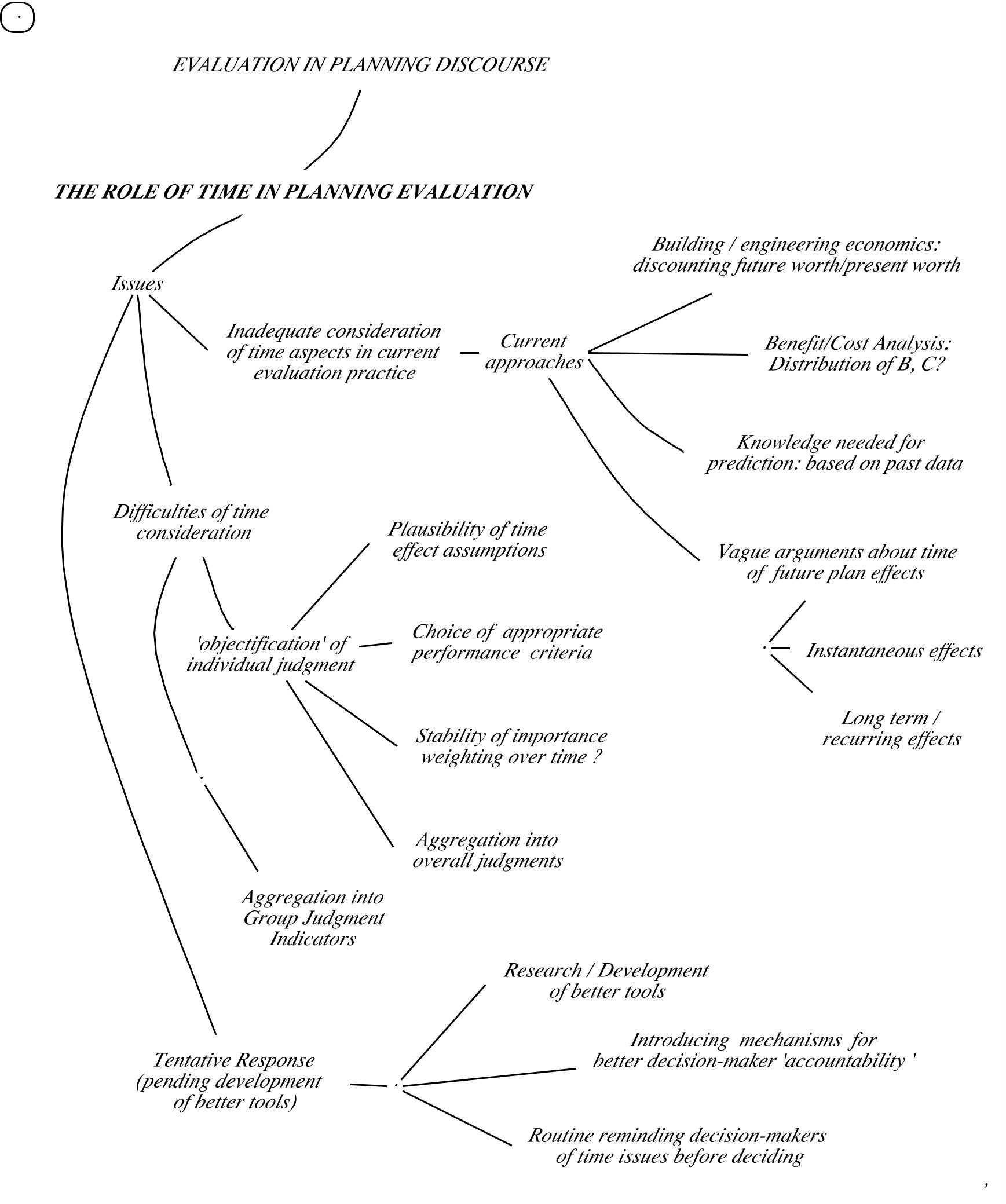
Other issues related to time have often been inadequately dealt with in evaluation of any kind:
Estimates of plan consequences over time
All planning arguments are expressing people’s expectations of the plan’s effect in the future. Of course, we know that there are relatively few cases in which a plan or action will generate results that will materialize immediately upon implementation and then stay that way. So what do we mean when we offer an argument that a plan ‘will bring improve society’s overall health’ — even resorting to ‘precise ‘statistical’ indices like mortality rates, or life expectancy? We know that these figures will change over time, one proposed policy will bring more immediate results than another, but the other will have better effect in the long run; and again, the father into the future we look, the less certain we must be about our prediction estimates. These things are not easily expressed in even carefully crafted arguments supported by the requisite statistics: how should we score their plausibility?
Tentative insights, conclusions?
These ‘not fully resolved / more work needed’ questions may seem to strengthen the case for evaluation approaches other than trying to draw support for planning decisions from discourse contributions, even with more detailed assessment of arguments than shown here (examining the evidence and support for each premise). However, the problems emerging from the examination of the argumentative process do affect other evaluation tools as well. I have not seen approaches that resolve them all more convincingly. So: Some first tentative conclusions are that planning debate and discourse — too familiar and accessible to experts and lay people alike to be dismissed in favor of other methods — would benefit from enhancements such as the argument assessment tools, but also, opportunities and encouragement should be offered to draw upon other tools, as called for by the circumstances of each case and the complexity of the plans.
These techniques, methods, should be made available for use by experts and lay discourse participants, in a ‘toolkit’ part of a general planning discourse support platform — not as mandatory components of a general-purpose one-size-fit-all planning method but as a repository of tools for creative innovation and expansion: Because plans as well as the process that generate plans define those involved as ‘the creators of that plan’ , there will be a need to ‘make a difference, to make it theirs: by changing, adapting, expanding and using the tools in new and different ways, besides inventing new tools in the process.
References:
Rittel, Horst: “APIS: A Concept for an Argumentative Planning Information System” Institute of Urban and Regional Development, University of California at Berkeley, 1980 . A report about research activities conducted for the Commission of European Communities, Directorate General XIIA.
–o–


 Evaluation example 1: Steps of a ‘Group Formal Quality Evaluation’
Evaluation example 1: Steps of a ‘Group Formal Quality Evaluation’
