Thorbjørn Mann, July 2020
Some thoughts about ‘absolute truths’, systems thinking and humanity’s challenges. An exploration of knowledge needed for a discourse that I suggest is critically significant for systems thinking related to questions about what to do to about humanity’s big challenges. I apologize for the roundabout but needed explanation.
‘What better be done’: absolute truth?
There are recurring posts in Systems Thinking groups, that insist on decisions being made by focusing on the ‘right’ things’, or what better (best) be done, implying that what is ‘better be done’ is a matter of ‘absolute, objective truth’. Thus, any suggestions about the issue at hand are being derailed — dismissed — by calling them mere subjective opinions and by repeating the stern admonition to following the absolute truth of ‘doing what better be done’, as if all other suggestions were not already efforts to do so.
Questions about what those truths may be are sidestepped or answered by the claim that they are so absolute, objective and self-evidently true that they don’t need explanation or supporting evidence. Heretical questions about this are countered with the question such as “are you questioning that there are absolute truths”? Apart from the issue whether this may be a tactic by proponent of an answer (the one declared to be an absolute truth) to get the proponents’ answer accepted, is it an effort to sidestep the question of what should be done altogether stalling it in the motherhood issue of absolute truth? At any rate, raising questions.
Does this call for a closer examination about the notion of ‘absolute truths’, and how one can get to know them? What is an ‘absolute truth’ (as compared to about a not so absolute one?)
Needed distinctions
There may be some distinctions that need reminder (being old distinctions) and clarification, beginning with the following:
‘IS’- States of affairs in ‘reality’ versus statements about those
There exist situations, states of affairs ‘s’ constituting what we call ‘reality’. Existing, they ‘are’. Whether we know them or not; (mostly. we don’t.) And if we know and recognize such a state, we call it ‘true’. But isn’t that less a ‘property’ of a state ‘s’, than a label attached to the statement, about ‘s’? About ‘s’, is it not sufficient to simply say ‘it is’? So what do we mean by the expression ‘absolute truth’? As a a statement about ‘s’ , it would seem to imply that there are states of affairs that ‘are’ ‘absolutely true’ and others that aren’t? So would it not be necessary to offer an explanation of this difference? If there isn’t one, does the ‘absolute’ part become meaningless and unnecessary?
So the practical use of ‘true’ or ‘false’ really refers to statements, claims about reality, not reality itself. When we are describing a specific situation ‘s’ or even claiming that it exists, we are making a claim, a statement. When such a statement matches the actual state of affairs with regard to s, we feel entitled to say that the statement is ‘true’. Again: ‘truth’ is not a property of states of affairs but a judgment statement about ‘content’ statements or claims.
About the claims of a statement ‘matching’ the actual state of affairs. Do we really know ‘reality’, and how would we know? Discussions and attempted demonstrations about this tend to use simple concepts — for example: “How many triangles are depicted in this diagram?”. The simple ‘answers’ are both ‘obviously true’ (even though people are occasionally disagreeing even about those) — but upon examination based on different understood definitions of the concepts involved. The definitions are not always stated explicitly, which is a problem: it leads to the troublesome situation where one of disagreeing parties can honestly refer to answers based on ‘their’ definition’ as ‘true’ and to other answers as ‘false’ (and consequently questioning the sanity or goodwill intentions of anybody claiming otherwise). So are all those answers ‘absolutely true’ but only each given the appropriate related definitions and understanding?
The understanding of ‘triangle’ in the diagram example may be that of “three points not on the same straight line in a plane, connected by visible straight lines.” There may be a fixed ‘true’ number of such triangles in the diagram. But if the definition of ‘triangle’ is just “three points not on the same straight line'”, and it is left open whether the diagram itself intends to show a plane or a space, the answers become quite different and even uncountable (‘infinitely many, given the infinitely many points on a plane or in a space depicted by the diagram, that exist in triangular position relative to each other).
The term ‘depicted’ also requires explanation: does it only refer to triangles ‘identified’ by lines connecting three selected points, lines drawn by a color different from the color of the ‘plane (or space) of the diagram? If drawn by the same color, are they n o t ‘depicted’? Do the edges and corners of the diagram picture ‘count’ as ‘depicting’ the lines and apex of a triangle, or not? So even in this simple ‘noncontroversial’ example, there are many very plausible answers, and the decision to call one or some of them ‘absolute truth’ begins to look somewhat arbitrary.
Probability
The label ‘true’ or ‘false’ apply to existing or past states of affairs. Do they also apply to claims about the future (that is, to forecasts, predictions), The predicted states of affairs are, by definition, not ‘true’ yet. The best we can do is to say that such a statement is more or less ‘probable’: a matter of degrees we express by a number from 0 (totally unsure) to 1(virtually certain) or by a ‘percentage’ number between zero and 100.
Actually, we usually are not totally certain about the truth even of our claims about actual ‘current ‘ or ‘always’- states of affairs. We find that we often make such claims only to find out later that we were wrong, or only approximately right about a given situation. Even more so, about more complex claims such as whether a causes b and whiter it will do so in the future. But it is fair to say that when we make such claims, we aim and hope to be as close to the actual situation or effect as possible. Can we just say that we should acknowledge the degree of certainty — or ‘plausibility’ — of our statements? Or acknowledge that a speaker may be totally certain about their claim, but listeners are entitled to have and express less certainty — e.g by assigning a different certainty, probability or — I suggest –‘plausibility’ to the claim? Leaving a crumb of plausibility for the ‘black swan’?
‘OUGHT’ claims and their assessment: ‘Plausibility’ rather that ‘truth’
For some other kinds of claims, the labels ‘true’ or ‘false’ are plainly not appropriate, not even ‘probable’. Those are the ‘ought’-claims we use when discussing problem situations (understood as as discrepancies between what somebody considers to be the case or probable, and what that person feels ‘ought’ to be the case). The state of affairs we ‘ought’ to seek ( or the means we feel we ought to apply to achieve the desired state) are– equally by definition — not ‘true’ yet. So should we use a different term? I have suggested that the label ‘plausible’ may serve, for all these claims, expressed as a number n (for example ‘1’) between -n (totally implausible, virtually improbable or the opposite being true) and +n (virtually certain) with the midpoint zero denoting ”don’t know’, ‘can’t tell’. Reminder: these labels express just our states of knowledge or opinion, not the states of affairs to which they refer: we make decisions on the basis of our limited knowledge and opinions, not on reality itself (which we know only approximately or may be unsure about).
How can we gain plausibility of claims?
The question then is: How do we get to know whether any of these claims are ‘true’ or probable, or plausible, and to what degree? Matching? Or: — since we can rarely attain complete certainty (knowing that there can be ‘black swans’ to shatter that certainty) — how can we increase our degree of plausibility we feel we can attach to a given claim.? What are the means by which we gain plausibility about claims? Possibilities are:
1) For ‘fact’-claims:
1a) Personal observation, experiments, measurements, demonstration, ‘tests’.
1b) Inference from other fact-claims and observations, using ‘logically valid’ reasoning schemes;
1c) From ‘authorities’: other persons we trust to have properly done (1a) or (1b), and can or have explained this;
1d) Declaring them ”self-evident’ and thus not needing further explanation.
2) For ‘ought- claims:
2a) The items equivalent to (1a) obviously don’t apply: So: Personal preference, desire, need, accepted common goals or ‘laws’
2b) Inference? The problem here is that inferences with ‘ought or what I call ‘planning arguments’ — claims are inherently not (deductively) ‘valid’ from a formal logic point of view and because the label ‘true’ does not apply. However: for some of the factual premises in these arguments, reasons (1) will apply and are appropriate.
2c) From authorities: Either because they have done 2a or 2b, or because they have social status to ‘order’, command ought-claims?
2d) ‘Self-evidence’? For example: ‘moral norms’? Laws?
Is ‘self-evident’ equal to ‘absolute’?
We could add claims about ‘meaning’, definition etc. as a third category. For all, is the claims of ‘absolute truth” equivalent to ‘self-evident? It is the only one for which explanation justification, evidence is not offered, even claimed to be impossible, unneeded. What this means is: if there are differences of opinion about a claim, can the proponent of such a claim expect to persuade others to come to accept it as theirs? What if both parties should honestly claim / believe that theirs is the absolute truth? Claiming ‘absolute truth’ or ‘right’ or ‘self-evidence’ is not a good persuasion argument, but if repeated sufficiently often (brainwashing) surprisingly, effective, history tells us. If justification (e.g. by demonstration) is attempted, it turns into one of the other kinds.
So, for all these claims and their ‘justification’ support, different people can have different opinions (different plausibility degrees). This is all too frequently observed, and the source of all disagreements, quarrels, fights, wars. The latter item (war) suggest that there is a missing means for acquiring knowledge: the application of coercion. force, violence, or in the extreme, the annihilation of persons of different opinions. The omission is based on the feeling that it is somehow ‘immoral’ (no matter how frequently it is actually applied in human societies, from the upbringing of children to ‘law enforcement’ and warfare).
The need to shift attention to ‘decision criteria’ and modes acknowledging irreconcilable differences of opinion
There is, for all the goodwill admonished by religious, philosophical and political leaders, the problem that even with ample efforts of explanation and offering exhortation, reasons, arguments, definitions, situations may occur where agreement on the claims involved cannot be achieved — yet the emergencies, problems, challenges demand that ‘something must be done’.
What this means, in my opinion, is that the noble quest for ‘truth’, probability, even plausibility as the better guide for community, social decisions — ‘solution’ criteria — making decisions based on the basis of the merit (value, plausibility) of contributions to the discourse about what we ought to do (that we ideally would all agree on!) must be shifted to a different question: what criteria can we use to guide our decisions in the face of significant differences in our opinions about the information supplied in the discourse? The criteria for evaluation of quality, plausibility of proposed solutions should be part of but are not the same as the criteria for good decisions. It is interesting to note that the most common decision mode – voting — in effect dismisses all the merit concerns of the ‘losing’ minority. Arguably, it should be considered a crude crutch to the claim of ‘democratic’ ideals: equality, justice, fairness to all; But also, that the very crisis cry ‘”Something must be done” is often used as an exhortation tool to somehow generate ‘unity’ of opinions.
Issues for Systems Thinking
I suggest that this is an important set of issues for systems thinking. Systems Thinking has been claimed to offer ‘the best currently available foundation for tackling humanity’s challenges. But has it focused its work predominantly on the ‘IS’ questions of the planning and policy-making discourse, rather than on the ‘ought’ issues? On better understanding of the (existing) systems in we will have to interfere? On better prediction of different plan proposals’ future performance (simulation)? Sure, those tasks are immensely important and the work on these questions admirable. But are they the whole task?
As far as I can see, the other (‘ought’) part of planning and policy-making work — both the development of a) better evaluation, (development of measures of the merit of planning discourse contributions leading to ‘solution merit’ criteria) and b) the development of better criteria for planning decisions, in the face of acknowledged disagreement about the merit of information contributed to the discourse are at best still in the embryonic state. Systems thinking appears to many (perhaps unfairly so) as suggesting that decisions should be based on the assessment of ‘facts’ data alone, ignoring the proper assessment of ‘ought’ claims and how they must be combined with the ‘facts- claims to support better decisions.
The development of a better planning discourse platform
Of course, the ‘discourse’ itself about these issues is currently in a state that does not appear to lead to results for either of the above criteria: the design of the discourse for crafting meaningful decisions about humanity’s challenges is itself an urgent challenge. If I had not convinced myself, in the course of thinking about these issues, that ‘absolute truth’ is a somewhat inappropriate or even meaningless term, I would declare this a main ‘absolutely truth and important’ task we face.
–o–

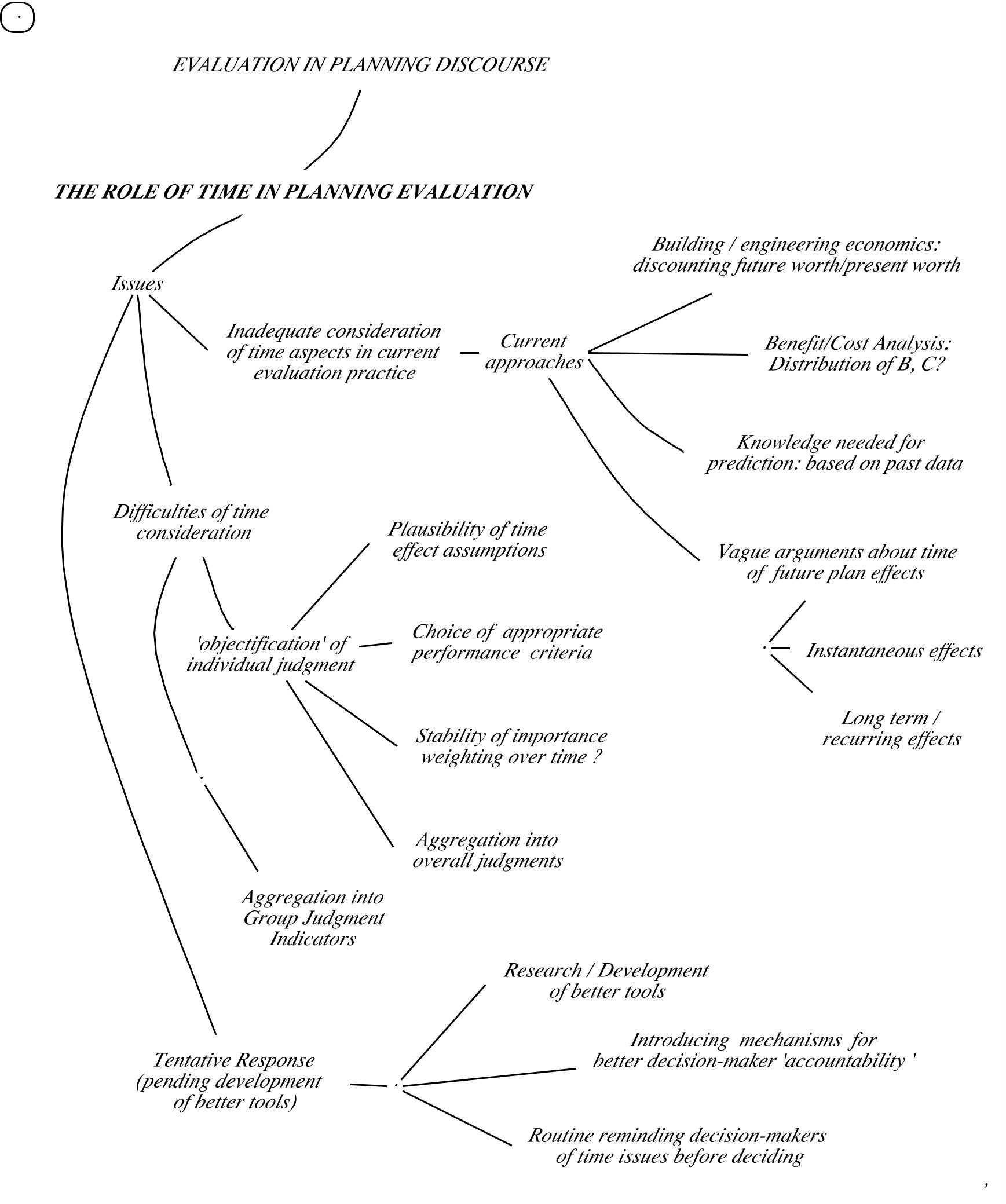
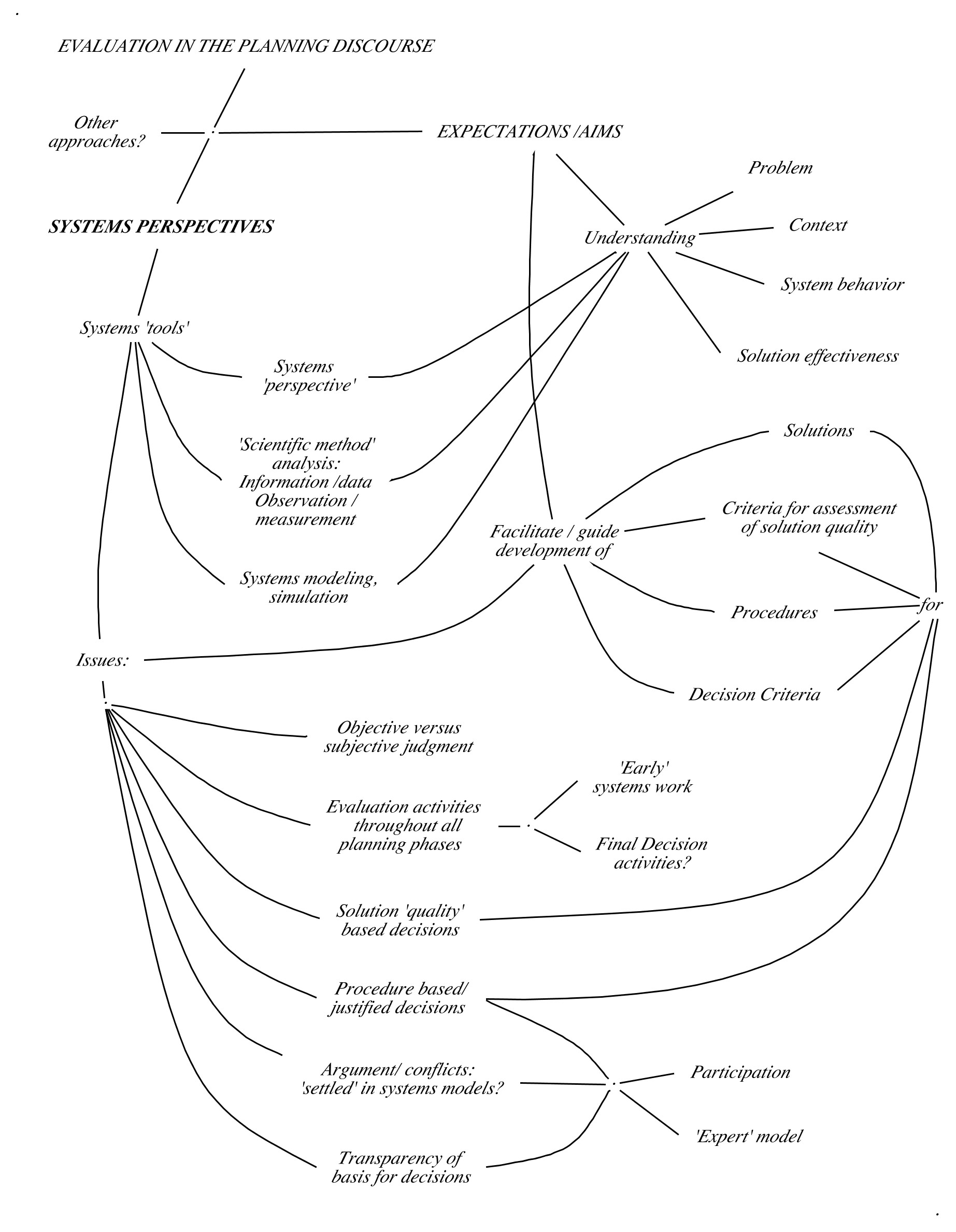

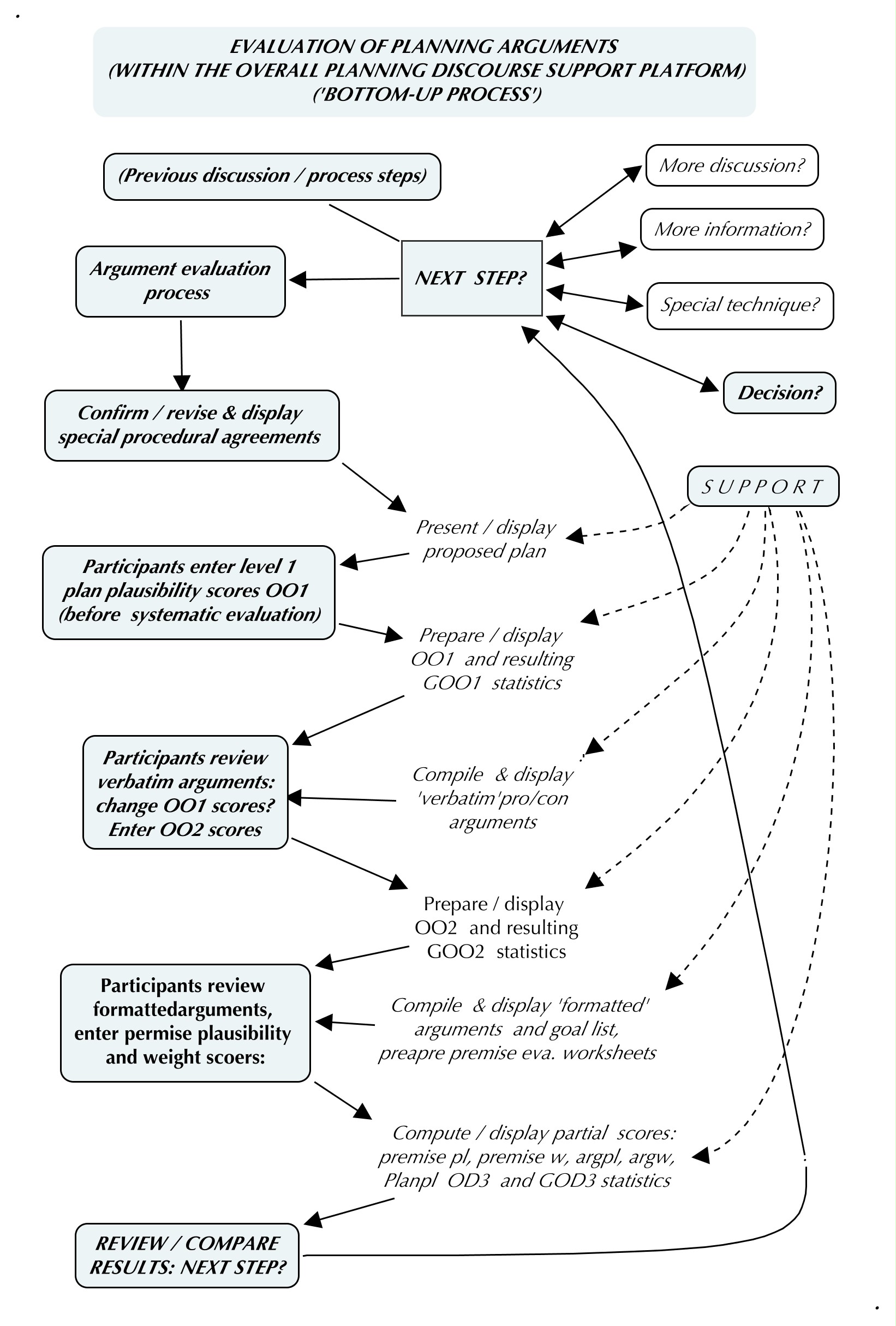
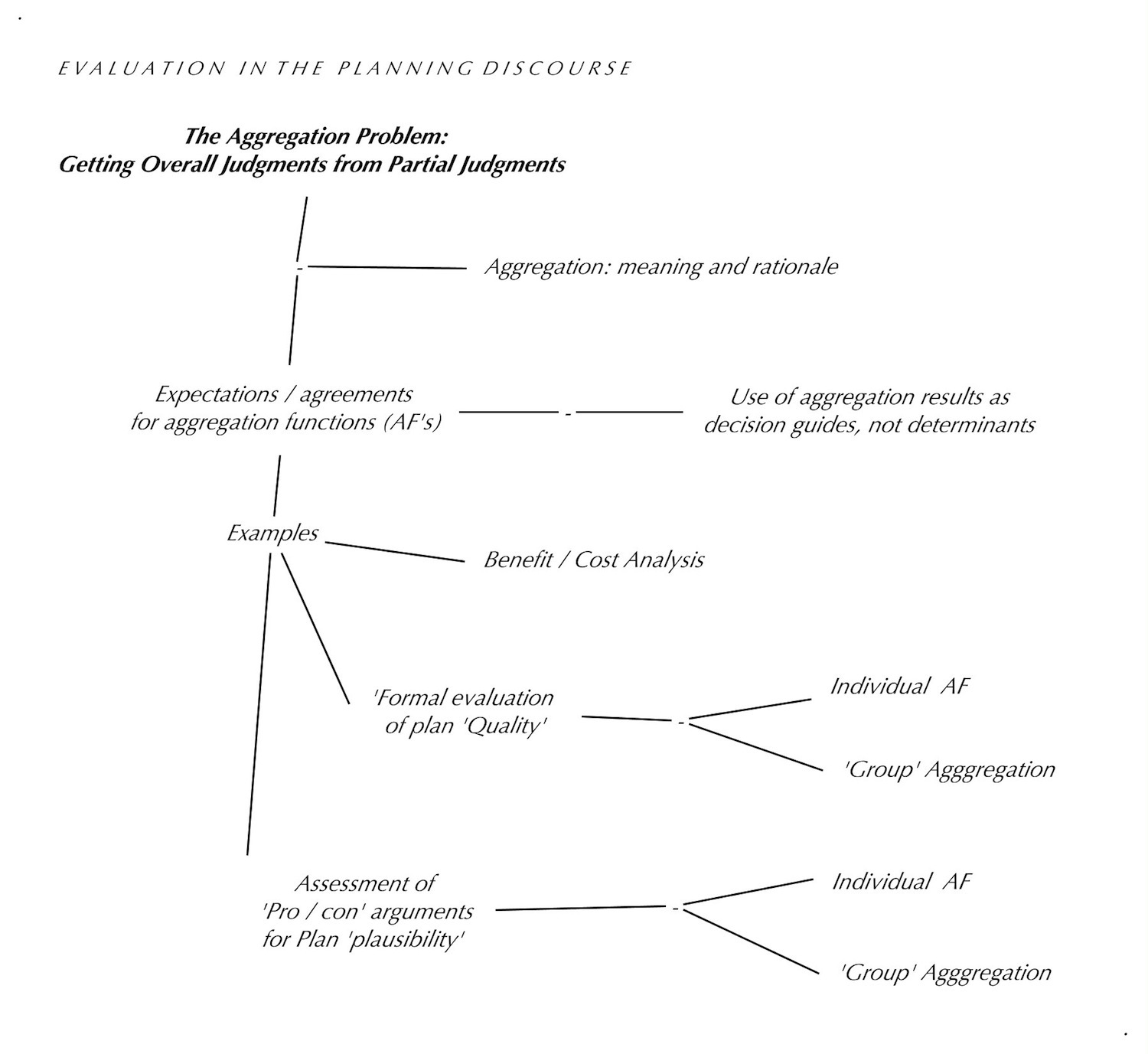
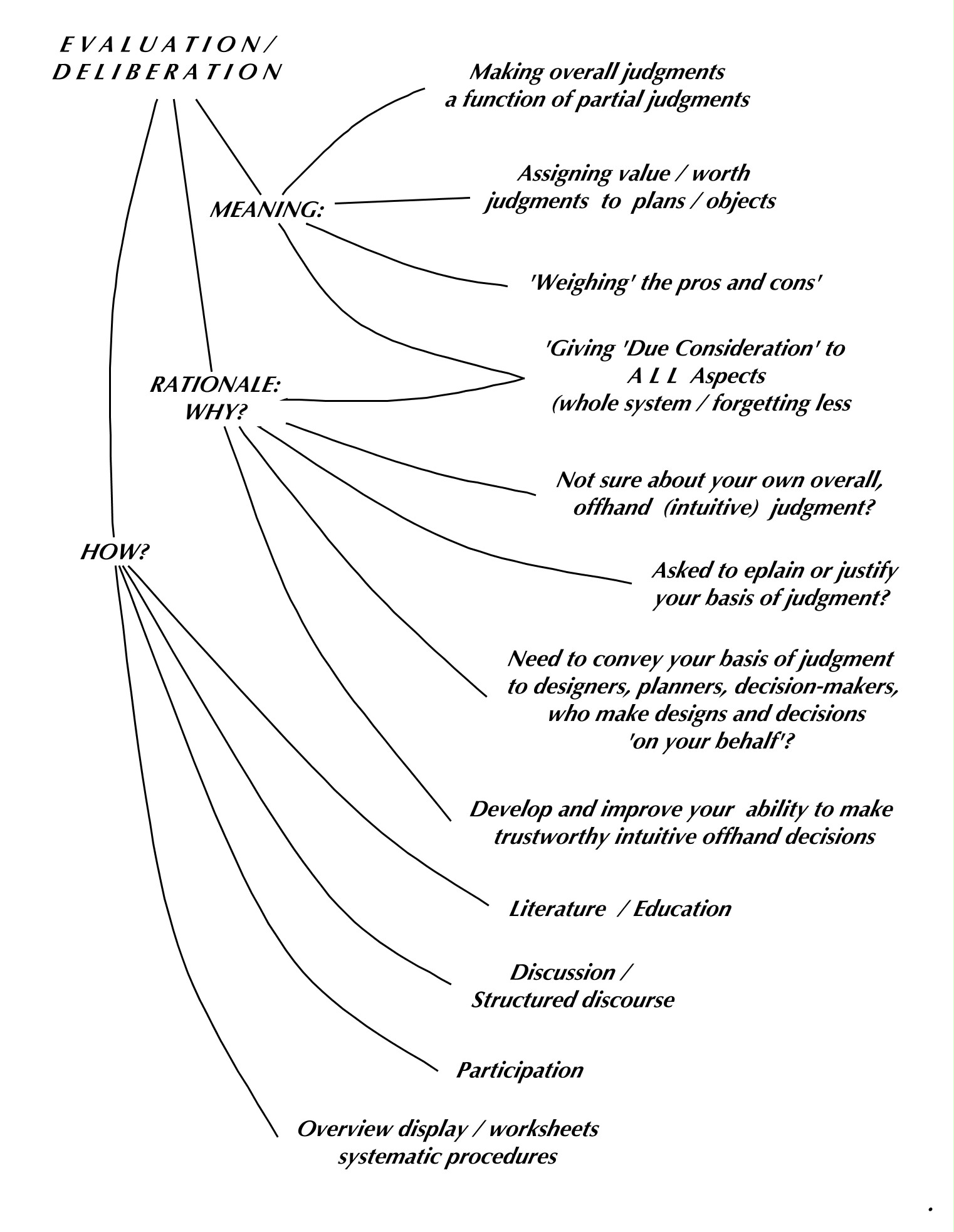
 Evaluation example 1: Steps of a ‘Group Formal Quality Evaluation’
Evaluation example 1: Steps of a ‘Group Formal Quality Evaluation’