An effort to clarify the role of evaluation in the planning process.
Thorbjørn Mann
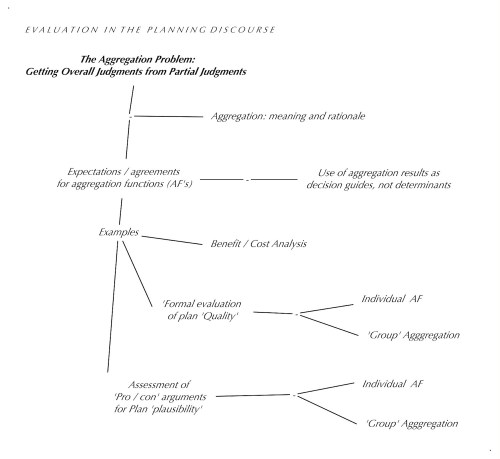
THE AGGREGATION PROBLEM:
Getting Overall Judgments from Partial Judgments
The concept of ‘deliberation’ was explained, in part, as the process of ‘making overall judgments a function of partial judgments’. We may have gone through the process of trying to explain our overall judgment about something to others, or made the effort of ‘giving due consideration’ to all aspects of the situation, we arrived at a set of partial judgments. Now the question becomes: just how do we‘assemble’ (‘aggregate’) these partial judgments into the overall judgment that can guide us in making the decision, for example, to adopt or reject the proposed plan.
The discussion has already gone past the level of familiar practices such as merely counting the number of supporting and opposing ‘votes’ and even some well-intentioned approaches that begin to look at the number of explanations (arguments or support statements) in the ‘breadth‘ (number of different aspects brought up by each supporting or opposing party, and ‘depth‘ — the number of levels of further support for the premises and assumptions of the individual arguments.
The reason why these approaches are not satisfying is that neither of them even begin to consider the validity, truth and probability (or more generally: plausibility), weight or relevance of any of the aspects discussed, or whether the judgments about any such aspects or justifications even have been ‘duly considered’ and understood.
Obviously, it is the content merit, validity, the ‘weight’ of arguments etc. we try to bring to bear on the decision. Do we have better, more ‘systematic’ ways to do this than Ben Franklin’s suggestion? (He recommended to write up the pros and cons in two different columns on a sheet of paper, then look at pairs of pros and cons that carry approximately equal weight and cancel each other out, and cross those pairs out, until there are the remaining arguments left that do not have any opposing reasons in the opposite column: those are the ones that should tilt the decision towards approval or rejection.)
What we have, on the one hand, is the impressively quantitative ‘Benefit/Cost’ approach, that works by assigning monetary value to all the b e n e f i t s of a proposed plan (the ‘pro’ arguments), and compare those with the monetary value of the ‘c o s t’ of implementing it. It has run into considerable criticism, mainly for the reasons that the ‘moral’ reluctance of having to assign monetary value to people’s health, happiness, lives; the fact that the approach usually has to be done by ‘experts’, not by citizens or affected groups, and from the overall point of view of some overall ‘common good’ perspective that is the usually ‘biased’ perspective of the government currently in power, that may not be shared by all segments of society, because it tends to hide the issue of the distribution of benefits and costs: inequality.
On the other hand, we have the approaches that separate the ‘description’ of the evaluated plan or object to be evaluated from the perceived ‘goodness’ (‘quality’) judgments about the plan and its expected outcome, from the‘validity’ (plausibility, probability) of the statements (arguments) conveying the claims about those outcomes. And, so far, the assumption that ‘everybody‘ including all ‘affected’ parties can make such judgments and ‘test’ their merit in a participatory discourse. What is still missing are the possible ways in which they can be ‘aggregated’ into overall judgments and guiding measures of merit for the decision– first, for individuals, and then for any groups that will have to come to a commonly supported decision. This is the topic to be discussed under the heading of ‘aggregation’ and ‘aggregation functions’ — the rules for getting ‘overall’ judgments from partial judgments and ‘criterion function’ results.
It turns out that there are different possible rules about this, assumptions that must be agreed upon in each evaluation situation, because they result in different decisions: The following are some considerations about assumptions or expectations for ‘aggregation functions (suggested in H. Rittel’s UC Berkeley lectures on evaluation, and listed in H. Dehlingers article “Deontische Fragen: Urteilsbildung und Bewertungssysteme” in “DIe methodische Bewertung: Ein Instrument des Architekten” Festschrift zum 65. Geburtstag von Prof. Arne Musso, TU Berlin, 1993):
Possible expectation considerations for aggregation functions:
1 Do we wish to arrive at a single overall judgment (of quality / goodness or plausibility etc.) — one that can help us distinguish between e.g. plan alternatives of greater or lesser goodness?
2 Should the judgments be expressed on a commonly agreed-upon judgment scale whose end points and interim values ‘mean’ the same for all participants in the exercise? For example, should we agree that the end points of a ‘goodness’ judgment scale should mean ‘couldn’t possibly be better’ and ‘couldn’t possibly be worse’, respectively; and that there should be a ‘midpoint ‘ meaning’ neither good nor bad; indifferent; or ‘don’t know, can’t make a judgment’? (Most judgments scales in practice are expressed on a ‘zero to some ‘one-directed’ scale such as zero to some number.)
3 Should the judgment scale be the same at all levels of the aspect tree, to maintain consistency of the meaning of scores at all levels? So any equations for the aggregation functions should be designed to produce the respective overall judgment at the next higher level to be a score on the same scale.
4 Should the aggregation function ensure that if a partial score is improved, the resulting overall score should also be higher or the same, but not lower (‘worse’) than the unimproved score? By the same rule, the overall score should not be better than the previous score, if one of the partial judgments becomes lower than before.
This expectation means that in a criterion function, the line showing the judgments cores should be steadily declining and decreasing, but not have sudden spikes or valleys.
5 Should the overall score be the highest one (say, +3 = ’couldn’t be better’, on a +3/-3 scale) only if all partial scores are +3?
6 Should the overall score be a result of ‘due consideration’ of all the partial scores?
7a Should the overall score be ‘couldn’t be worse’ (e.g. -3 on the +3/-3 scale) if all partial scores are -3?
Or
7b Should the overall score become -3 if one of the partial scores becomes -3 and thus unacceptable?
Different functions — equations of ‘summing up partial judgments — will be needed for this. There will be situations or tasks in which aggregation functions meeting expectation 7b may be needed. There is no one aggregation function meeting all these expectations. Thus, the choice of aggregation functions must be discussed and agreed upon in the process.
Examples:
‘Formal’ Evaluation process for Plan ‘Quality’
Individual Assessment
The aggregation functions that can be considered for individual ‘quality’ evaluation (deliberating goodness judgments, aspect trees, and criteria i what may be called ‘formal evaluation procedures’) include the following:
Type I: ‘Weigthed average’ function: Q = ∑ (qi * wi)
where Q is the overall deliberated ‘quality’ or ‘goodness’ score; qi is the partial score of aspect or sub-aspect i, n is the number of aspects at that level; wi is the weight of relative importance of aspect i, on a scale of 0 ≤ wi ≤ 1 and such that ∑wi = 1. This is needed to ensure that Q will be on the same scale (and the associated meaning of the resulting judgment score the same) as q.
This function does not meet expectation 7b; it allows ‘poor scores’ on some aspects to be compensated for by good scores on other aspects.
Type II a: (“the chain as strong as its weakest link” function): Q = Min (qi)
Type IIb: Q = ∏ ((qi + u) ^wi ) – u
Here, Q is the overall score, qi the partial score i of n aspects, and u is the extreme value of the judgment score (e.g. 3 in the above examples). This function, (multiplying all the components of (qi + u) with the exponent of their weights wi, and then subtracting u from the result to get the overall score back to the +3/-3 scale) acts much like the type I function as long as all the scores are in the positive range, but pulls the overall score the closer to -u , the lower one of the scores comes to – u, the ‘unacceptable’ performance or quality. (Example: if the structural stability of a building does not stand up against expected loads, it does not matter how otherwise functionally adequate or aesthetically pleasing it is: its evaluation should express that it should not be built.)
Group assessments:
Individual scores from these functions can be applied to get statistical ‘Group’ indicators GQ : for example:
GQ = 1/m ∑ Qj
This is the average or mean of all individual Qj scores for all m participants j.
GQ = Qj
This takes the judgment of one group member as the group score.
GQ = Min (Qj)
The group score is equal to the score of the member with the lowest score in the group; both these functions effectively make one participant the ‘dictator’ of the group…
Different functions should be explored that, for example, would consider the distribution of the improvement of scores for a plan, compared with the existing or expected situation the plan is expected to remedy. For example, the form of aggregation function type IIb could also be used for group judgment aggregation.
The use of any of these aggregated, (‘deliberated’ ) judgment scores as a ‘direct’ guiding measure of performance determining the decision c a n n o t be recommended: they should be considered decision guides, not determinants. For one, the expectation of ‘due consideration of all aspects‘ would require complete knowledge of all consequences of a plan and causes of the problem it aims to fix — an expectation that must be considered unrealistic in many situations but especially in ‘wicked’ problems or ‘messes’. There, decision-makers must be willing to assume responsibility for the possibility of being wrong — a condition impossible to deliberate, by definition, when caused by ignorance of what we might be wrong about.
Aggregation functions for developing overall ‘Plan plausibility’ judgment
from the evaluation of ‘pro’ and ‘con’ arguments.
Plausibility judgments
It is necessary to reach agreements about the use of terms for the merit of judgments about plans as derived from argument evaluation, because the evaluation task for planning arguments is somewhat different from the assessment usually applied to arguments. Traditionally, the purpose of argument analysis and evaluation is seen as that of verifying whether a claim — the ‘conclusion’ of an argument — is true or false, and this is seen as depending on the truth of the premises of the argument and the ‘validity’ of the form or pattern or ‘inference rule’ of the argument. These criteria do not apply to planning arguments, that can generally be represented as follows: (Stating the ‘conclusion’ — the claim about a proposed plan A first:)
Plan A ought to be implemented
because
Plan A will result in outcome B, (given or assuming conditions C);
and
Outcome B ought to be aimed for / pursued;
and
Conditions C are given (or will be when the plan is implemented)
Like many arguments studied by traditional logic and rhetoric, not all argument premises are stated explicitly in discussions; some being assumed as ‘taken for granted’ by the audience: ‘Enthymemes’. But to evaluate these arguments, all premises must be stated and considered explicitly.
This argument pattern — and its variations due to different constellations of assertion or negation of different premises — does not conform to the validity conditions for ‘valid’ arguments in the formal logic sense: it is, at best inconclusive. Its premises cannot be established as ‘true or false‘ — the proposed plan is discussed precisely because it as well as the outcomes B aren’t there (‘true’) yet. This also means that some of the premises — the factual-instrumental claim ‘If A is implemented, then B will happen, given C) and the claim ‘C will be present’ are estimates or predictions qualified as probabilities. And ‘B ought to be pursued’ as well as the conclusions ‘A ought to be implemented) are neither adequately called ‘probable’ nor true or false: the term ‘plausible’ seems more fitting at least for some participants, but not necessarily for all. Indeed: ‘plausible’ judgments may be applied to all the claims, with the different interpretations easily understood to each kind. This is is a matter of degrees, not a binary yes/no quality. And unlike the assessment of factual and even probability claims in common logic argumentation studies, the ‘conclusion’ (decision to implement) is not determined by a single ‘clinching’ argument: it rests on several or many ‘pros and cons’ that must be weighed against each other. That is the evaluation task for planning argumentation, that will lead to different ‘aggregation’ tools.
The logical structure of planning argumentation can be stated in simplified for as follows:
– An individual’s overall plausibility judgment of plausibility PLANPL is a function of the ‘weight’ Argw of the various pro and con arguments raised about the proposal.
– The argument weight is a function of the argument’s plausibility Argpl and the weight of relative importance w of its deontic (ought-) premise.
– The Argument plausibility Argpl is a function of the plausibility of its premises.
Examples of aggregation functions for this process might be the following:
1. a Argument plausibility: Argpli = ∏ {Premplj} for all n premises j.
Or
1.b Argpli = Min{ Premplj}
2. Argument weight: Argwi = Argpli * wi with 0 ≤ wi and ∑ wi = 1
for the ought-premises of all m arguments
3. Proposal plausibility PLANPL = ∑ Argwi
Aggregation functions for Group judgment statistics: (Similar to the Quality group aggregations)
Mean Group average plausibility GPLANPL = 1/k ∑ PLANPLp for all k participants p.
There are of course other statistical measures of the set of individual plausibility judgments that can be examined and discussed. Like the ‘Quality’ Aggregated measures, these ‘Group’ plausibility statistics should not be used as decision determinants but as guides, for instance as indicators of need for further discussion and explanation of judgment differences, or for revision of plan details to alleviate concerns leading to large judgment differences.
Comments? Additions?
–o–

0 Responses to “EVALUATION IN THE PLANNING DISCOURSE — AGGREGATION”