A tavern discussion looking at the idea of an artificial planning discourse participant from the perspectives of the argumentative model and the systems thinking perspectives, expanding both (or mutually patching up their shortcomings), and inadvertently stumbling upon potential improvements upon the concept of democracy.
Customers and patron of a fogged-in island tavern with nothing better to do,
awaiting news on progress on the development of a better planning discourse
begin an idly speculative exploration of the idea of an artificial planner:
would such a creature be a better planning discourse participant?
– Hey Bog-Hubert: Early up and testing Vodçeks latest incarnation of café cataluñia forte forte? The Fog Island Tavern mental alarm clock for the difficult-to-wakeup?
– Good morning, professor. Well, have you tried it? Or do you want to walk around in a fogged-in-morning daze for just a while longer?
– Whou-ahmm, sorry. Depends.
– Depends? On what?
– Whether this morning needs my full un-dazed attention yet.
– Makes sense. Okay. Let me ask you a question. I hear you’ve been up in town. Did you run into Abbé Boulah, by any chance? He’s been up there for a while, sorely neglecting his Fog Island Tavern duties here, ostensibly to help his buddy at the university with the work on his proposals for a better planning discourse system. Hey, Sophie: care to join us?
– Okay, good morning to you too. What’s this about a planning system?
– I’m not sure if it’s a ‘system’. I was asking the professor if he has heard whether Abbé Boulah and his buddy have made any progress on that. It’s more like a discourse platform than a ‘system’ – if by ‘system’ you mean something like an artificial planning machine – a robot planner.
– Oh, I’m relieved to hear that.
– Why, Sophie?
– Why? Having a machine make our plans for our future? That would be soo out of touch. Really. Just when we are just beginning to understand that WE have to take charge, to redesign the current ‘MeE’ system, from a new Awareness of the Whole, of our common place on the planet, in the universe, our very survival as a species? That WE have to get out from under that authoritarian, ME-centered linear machine systems thinking, to emerge into a sustainable, regenerative NEW SYSTEM?
– Wow. Sounds like we are in more trouble than I thought. So who’s doing that, how will we get to that New System?
– Hold on, my friends. Lets not get into that New System issue again – haven’t we settled that some time ago here – that we simply don’t know yet what it should be like, and should try to learn more about what works and what doesn’t, before starting another ambitious grand experiment with another flawed theory?
– Okay, Vodçek, good point. But coming to think about it – to get there, — I mean to a better system with a better theory — wouldn’t that require some smart planning? You can’t just rely on everybody coming to that great awareness Sophie is taking about, for everything just to fall into place? So wouldn’t it be interesting to just speculate a bit about what your, I mean Abbé Boulah’s buddy’s planning machine, would have to do to make decent plans?
– You mean the machine he doesn’t, or, according to Sophie, emphatically shouldn’t even think about developing?
– That’s the one.
– Glad we have that cleared up… Well, since we haven’t heard anything new about the latest scandals up in town yet, it might be an interesting way to pass the time.
– Hmm.
– I hear no real objections, just an indecisive Hmm. And no, I don’t have any news from Abbé Boulah either – didn’t see him. He tends to stay out of public view. So it’s agreed. Where do we start?
– Well: how about at the beginning? What triggers a planning project? How does it start?
Initializing triggers for planning?
– Good idea, Sophie. Somebody having a problem – meaning something in the way things are, that are perceived as unsatisfactory, hurtful, ugly, whatever: not the way they ought to be?
– Or: somebody just has a bright idea for doing something new and interesting?
– Or there’s a routine habit or institutional obligation to make preparations for the future – to lay in provisions for a trip, or heating material for the winter?
– Right: there are many different things that could trigger a call for ‘doing something about it’ – a plan. So what would the machine do about that?
– You are assuming that somebody – a human being – is telling the machine to do something? Or are you saying that it could come up with a planning project on its own?
– It would have to be programmed to recognize a discrepancy between what IS and what OUGHT to be, about a problem or need, wouldn’t it? And some human would have had to tell him that. Because it’s never the machine (or the human planner working on behalf of people) hurting if there’s a problem; its only people who have problems.
– So it’s a Him already?
– Easy, Sophie. Okay: A She? You decide. Give her, him, it a name. So we can get on with it.
– Okay. I’d call it the APT – Abominable Planning Thing. And it’s an IT, a neuter.
– APT it is. Nicely ambiguous… For a moment I thought you meant Argumentative Planning Tool. Or Template.
– Let’s assume, for now, that somebody told it about a problem or a bright idea. So what would that APT do?
Ground rules, Principles?
Due consideration of all available information;
Whole system understanding guiding decisions
towards better (or at least not worse) outcomes
for all affected parties
– Wait: Shouldn’t we first find out some ground rules about how it’s going to work? For example, it wouldn’t do to just come up with some random idea and say ‘this is it’?
– Good point. You have any such ground rules in mind, professor?
– Sure. I think one principle is that it should try to gather and ‘duly consider’ ALL pertinent information that is available about the problem situation. Ideally. Don’t you agree, Sophie? Get the WHOLE picture? Wasn’t that part of the agenda you mentioned?
– Sounds good, professor. But is it enough to just ‘have’ all the information? Didn’t someone give a good description of the difference between ‘data’ (just givens, messages, numbers etc) and ‘information’ – the process of data changing someone’s stat of knowledge, insight, understanding?
– No, you are right. There must be adequate UNDERSTANDING – of what it means and how it all is related.
– I see a hot discussion coming up about what that really means: ‘understanding’… But go on.
– Well, next: wouldn’t we expect that there needs to be a process of developing or drawing a SOLUTION or a proposed PLAN – or several – from that understanding? Not just from the stupid data?
– Det er da svœrt så fordringfull du er idag, Sophie: Now you are getting astoundingly demanding here. Solutions based on understanding?
– Oh, quit your Norwegian bickering. I’ll do even more demanding: Mustn’t there be a way to CONNECT all that understanding, all the concerns, data, facts, arguments, with any proposed DECISION, especially the final one that leads to action, implementation. If we ever get to that?
– Are you considering that all the affected folks will expect that the decision should end up making things BETTER for them? Or at least not WORSE than before? Would that be one of your ground rules?
– Don’t get greedy here, Vodçek. The good old conservative way is to ask some poor slobs to make some heroic Sacrifices for the Common Good. “mourir pour des idées, d’accord, mais de mort lente…” as George Brassens complains. But you are right: ideally, that would be a good way to put the purpose of the effort.
– All right, we have some first principles or expectations. We’ll probably add some more of those along the way, but I’d say it’s enough for a start. So what would our APT gizmo do to get things moving?
Obtaining information
Sources?
– I’d say it would start to inquire and assemble information about the problem’s IS state, first. Where is the problem, who’s hurting and how, etc. What caused it? Are there any ideas for how to fix it? What would be the OUGHT part — of the problem as well as a bright idea as the starting point?
– Sounds good, Bog-Hubert. Get the data. I guess there will be cases where the process actually starts with somebody having a bright idea for a solution. But that’s a piece of data too, put it in the pile. Where would it get all that information?
– Many sources, I guess. First: from whoever is hurting or affected in any way.
– By the problem, Vodçek? Or the solutions?
– Uh, I guess both. But what if there aren’t any solutions proposed yet?
– It means that the APT will have to check and re-check that whenever someone proposes a solution — throughout the whole process, doesn’t it? It’s not enough to run a single first survey of citizen preferences, like they usually do to piously meet the mandate for ‘citizen participation’. Information gathering, research, re-research, analysis will accompany the whole process.
– Okay. It’s a machine, it won’t get tired of repeated tasks.
– Ever heard of devices overheating, eh? But to go on, there will be experts on the particular kind of problem. There’ll be documented research, case studies from similar events, the textbooks, newspapers, letters to the editor, petitions, the internet. The APT would have to go through everything. And I guess there might have to be some actual ‘observation’, data gathering, measurements.
Distinctions, meaning
Understanding
– So now it has a bunch of stuff in its memory. Doesn’t it have to sort it somehow, so it can begin to do some real work on it?
– You don’t think gathering that information is work, Sophie?
– Sure, but just a bunch of megabytes of stuff… what would it do with it? Don’t tell me it can magically pull the solution from that pile of data!
– Right. Some seem to think they can… But you’ll have to admit that having all the information is part of the answer to our first expectation: to consider ALL available information. The WHOLE thing, remember? The venerable Systems Thinking idea?
– Okay. If you say so. So what to you mean by ‘consider’ – or ‘due consideration’? Just staring at the pile of data until understanding blossoms in your minds and the solution jumps out at you like the bikini-clad girl out of the convention cake? Or Aphrodite rising out of the data ocean?
– You are right. You need to make some distinctions, sort out things. What you have now, at best, are a bunch of concepts, vague, undefined ideas. The kind of ‘tags’ you use to google stuff.
– Yeah. Your argumentation buddy would say you’d have to ask for explanations of those tags – making sure it’s clear what they mean, right?
– Yes. Now he’d also make the distinction that some of the data are actual claims about the situation. Of different types: ‘fact’-claims about the current situation; ‘ought’ claims about what people feel the solution should be. Claims of ‘instrumental’ knowledge about what caused things to become what they are, and thus what will happen when we do this or that: connecting some action on a concept x with another concept ‘y’ – an effect. Useful when we are looking for x’s to achieve desired ‘y’s that we want – the ‘ought’ ideas – or avoid the proverbial ‘unexpected / undesirable’ side-and after-effect surprises of our grand plans: ‘How’ to do things.
– You’re getting there. But some of the information will also consist of several claims arranged into arguments. Like: “Yes, we should do ‘x’ (as part of the plan) because it will lead to ‘y’, and ‘y’ ought to be…” And counterarguments: “No, we shouldn’t do ‘x’ because x will cause ‘z’ which ought not to be.”
– Right. You’ve been listening to Abbé Boulah’s buddy’s argumentative stories, I can tell. Or even reading Rittel? Yes, there will be differences of opinion – not only about what ought to be, but about what we should do to get what we want, about what causes what, even about what Is the case. Is there an old sinkhole on the proposed construction site? And if so, where? That kind of issue. And different opinions about those, too. So the data pile will contain a lot of contradictory claims of all kinds. Which means, for one thing, that we, –even Spock’s relative APT — can’t draw any deductively valid conclusions from contradictory items in the data. ‘Ex contradictio sequitur quodlibet’, remember – from a contradiction you can conclude anything whatever. So APT can’t be a reliable ‘artificial intelligence’ or ‘expert system’ that gives you answers you can trust to be correct. We discussed that too once, didn’t we – there was an old conference paper from the 1990s about it. Remember?
– But don’t we argue about contradictory opinions all the time – and draw conclusions about them too?
– Sure. Living recklessly, eh? All the time, and especially in planning and policy-making. But it means that we can’t expect to draw ‘valid’ conclusions that are ‘true or false’, from our planning arguments. Just more or less plausible. Or ‘probable’ – for claims that are appropriately labeled that way.
Systems Thinking perspective
Versus Argumentative Model of Planning?
– Wait. What about the ‘Systems Thinking’ perspective — systems modeling and simulation? Isn’t that a better way to meet the expectation of ‘due consideration’ of the ‘whole system’? So should the APT develop a systems model from the information it collected?
– Glad you brought that up, Vodçek. Yes, it’s claimed to be the best available foundation for dealing with our challenges. So what would that mean for our APT? Is it going to have a split robopersonality between Systems and the Argumentative Model?
– Let’s look at both and see? There are several levels we can distinguish there. The main tenets of the systems approach have to do with the relationships between the different parts of a system – a system is a set of parts or entities, components, that are related in different ways – some say that ‘everything is connected / related to everything else’ – but a systems modeler will focus on the most significant relationships, and try to identify the ‘loops’ in that network of relationships. Those are the ones that will cause the system to behave in ways that can’t be predicted from the relationships between any of the individual pairs of entities in the network. Complexity; nonlinearity. Emergence.
– Wow. You’re throwing a lot of fancy words around there!
– Sorry, Renfroe; good morning, I didn’t see you come in. Doing okay?
– Yeah, thanks. Didn’t get hit by a nonlinearity, so far. This a dangerous place now, for that kind of thing?
– Not if you don’t put too much brandy in that café cataluñia Vodçek is brewing here.
– Hey, lets’ get back to your systems model. Can you explain it in less nonlinear terms?
– Sure, Sophie. Basically, you take all the significant concepts you’ve found, put them into a diagram, a map, and draw the relationships between them. For example, cause-effect relationships; meaning increasing ‘x’ will cause an increase in ‘y’. Many people think that fixing a system can best be done by identifying the causes that brought the state of affairs about that we now see as a problem. This will add a number or new variables to the diagram, to the ‘understanding’ of the problem.
– They also look for the presence of ‘loops’ in the diagram, don’t they? – Where cause-effect chains come back to previous variables.
– Right, Vodçek. This is an improvement over a simple listing of all the pro and con arguments, for example – they also talk about relationships x – y, but only one at a time, so you don’t easily see the whole network, and the loops, in the network. So if you are after ‘understanding the system’, seeing the network of relationships will be helpful. To get a sense of its complexity and nonlinearity.
– I think I understand: you understand a system when you recognize that it’s so loopy and complex and nonlinear that its behavior can’t be predicted so it can’t be understood?
– Renfroe… Professor, can you straighten him out?
– Sounds to me like he’s got it right on, Sophie. Going on: Of course, to be really helpful, the systems modeler will tell you that you should find a way to measure each concept, that is, find a variable – a property of the system that can be measures with precise units.
– What’s the purpose of that, other than making it look more scientific?
– Well, Renfroe, remember the starting point, the problem situation. Oh, wait, you weren’t here yet. Okay; say there’s a problem. We described it as a discrepancy between what somebody feels Is the case and what Ought to be. Somebody complains about it being too hot in here. Now just saying: ‘it’s too hot; it ought to be cooler’, is a starting point, but in order to become useful, you need to be able to say just what you mean by ‘cooler’. See, you are stating the Is/Ought problem in terms of the same variable ‘temperature’. So too even see the difference between Is and Ought, you have to point to the levels of each. 85 degrees F? Too hot. Better: cool it to 72. Different degrees or numbers on the temperature scale.
– Get it. So now we have numbers, math in the system. Great. Just what we need. This early in the morning, too.
– I was afraid of that too. It’s bound to get worse…nonlinear. So in the argumentative approach – the arguments don’t show that? Is that good or bad?
– Good question. Of course you can get to that level, if you bug them enough. Just keep asking more specific questions.
– Aren’t there issues where degrees of variables are not important, or where variables have only two values: Present or not present? Remember that the argumentative model came out of architectural and environmental design, where the main concerns were whether or not to provide some feature: ‘should the entrance to the building be from the east, yes or no?’ or ‘Should the building structure be of steel or concrete?’ Those ‘conceptual’ planning decisions could often be handled without getting into degrees of variables. The decision to go with steel could be reached just with the argument that steel would be faster and cheaper than concrete, even before knowing just by how much. The arguments and the decision were then mainly yes or no decisions.
– Good points, Vodçek. Fine-tuning, or what they call ‘parametric’ planning comes later, and could of course cause much bickering, but doesn’t usually change the nature of the main design that much. Just its quality and cost…
Time
Simulation of systems behavior
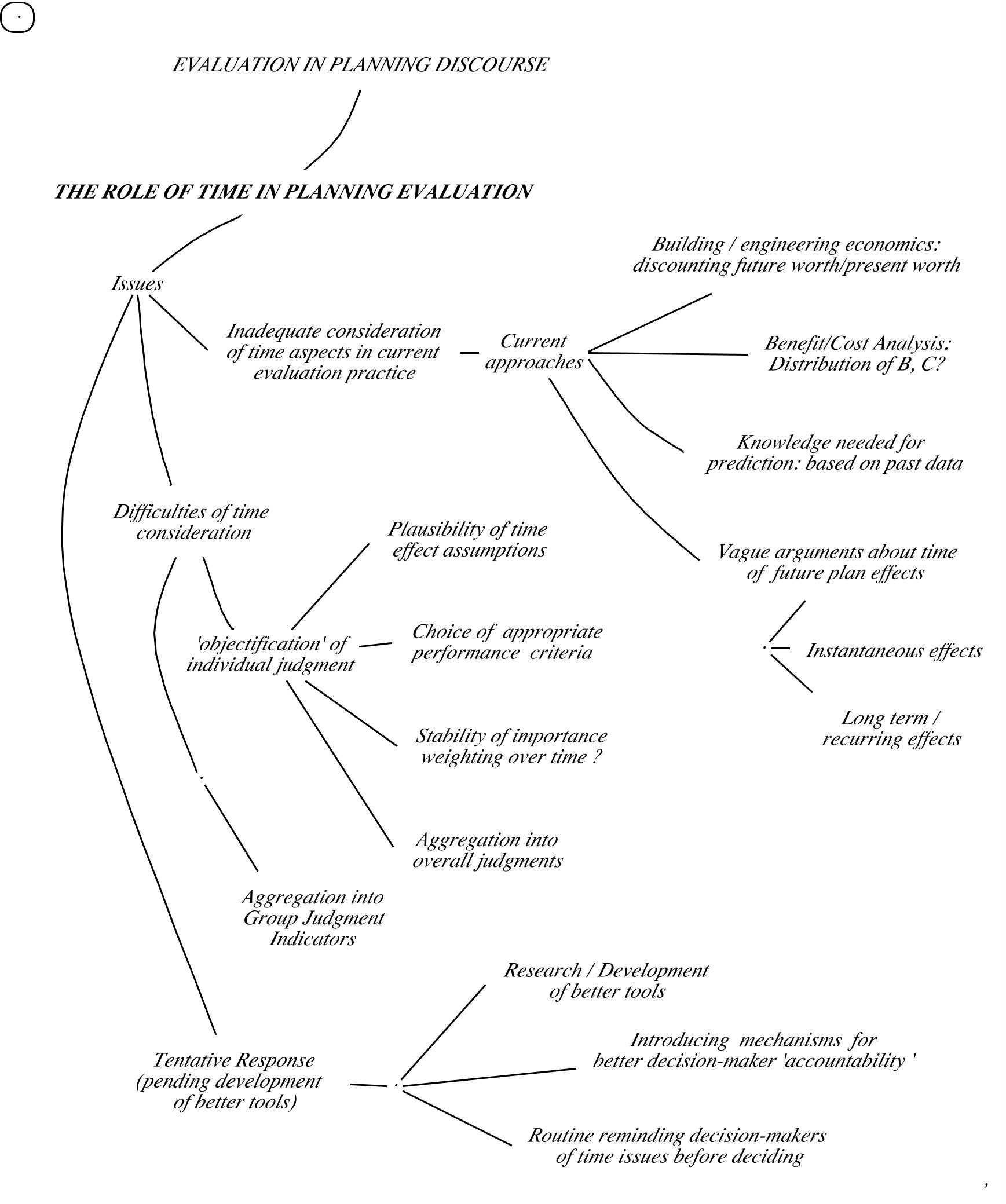
– Right. And they also didn’t have to worry too much about the development of systems over time. A building, once finished, will usually stay that way for a good while. But for policies that would guide societal developments or economies, the variables people were concerned about will change considerably over time, so more prediction is called for, trying to beat complexity.
– I knew it, I knew it: time’s the culprit, the snake in the woodpile. I never could keep track of time…
– Renfroe… You just forget winding up your old alarm clock. Now, where were we? Okay: In order to use the model to make predictions about what will happen, you have to allocate each relationship step to some small time unit: x to y during the first time unit; y to z in the second, and so on. This will allow you to track the behavior of the variables of the system over time, give some initial setting, and make predictions about the likely effects of your plans. The APT computer can quickly calculate predictions for a variety of planning options.
– I’ve seen some such simulation predictions, yes. Amazing. But I’ve always wondered how they can make such precise forecasts – those fine crisp lines over several decades: how do they do that, when for example our meteorologists can only make forecasts of hurricane tracks of a few days only, tracks that get wider like a fat trumpet in just a few days? Are those guys pulling a fast one?
– Good point. The answer is that each simulation only shows the calculated result of one specific set of initial conditions and settings of relationships equations. If you make many forecasts with different numbers, and put them all on the same graph, you’d get the same kind of trumpet track. Or even a wild spaghetti plate of tracks.
– I am beginning to see why those ‘free market’ economists had such an advantage over people who wanted to gain some control of the economy. They just said: the market is unpredictable. It’s pointless to make big government plans and laws and regulations. Just get rid of all the regulations, let the free market play it out. It will control and adapt and balance itself by supply and demand and competition and creativity.
– Yeah, and if something goes wrong, blame it on the remaining regulations of big bad government. Diabolically smart and devious.
– But they do appreciate government research grants, don’t they? Wait. They get them from the companies that just want to get rid of some more regulations. Or from think tanks financed by those companies.
– Hey, this is irresponsibly interesting but way off our topic, wouldn’t you say?
– Right, Vodçek. Are you worried about some government regulation – say, about the fireworks involved in your café catastrofia? But okay. Back to the issue.
– So, to at least try to be less irresponsible, our APT thing would have systems models and be able to run simulations. A simulation, if I understand what you were saying, would show how the different variables in the system would change over time, for some assumed initial setting of those variables. That initial setting would be different from the ‘current’ situation, though, wouldn’t it? So where does the proposed solution in the systems model come from? Where are the arguments? Does the model diagram show what we want to achieve? Or just the ‘current state’?
Representation of plan proposals
and arguments in the systems model?
Leverage points
– Good questions, all. They touch on some critical problems with the systems perspective. Let’s take one at a time. You are right: the usual systems model does not show a picture of a proposed solution. To do that, I think we’ll have to expand a little upon our description of a plan: Would you agree that a plan involves some actions by some actors, using some resources acting upon specific variables in the system? Usually not just one variable but several. So a plan would be described by those variables, and the additional concepts of actions, actor, resources etc. Besides the usual sources of plans, — somebody’s ‘brilliant idea’, some result of a team brainstorming session, or just an adaptation of a precedent, a ‘tried and true’ known solution with a little new twist, — the systems modeler may have played around with his model and identified some ‘leverage points’ in the system – variables where modest and easy-to-do changes can bring about significant improvement elsewhere in the system: those are suggested starting points for solution ideas.
– So you are saying that the systems tinkerer should get with it and add all the additional solution description to the diagram?
– Yes. And that would raise some new questions. What are those resources needed for the solution? Where would they come from, are they available? What will they cost? And more: wouldn’t just getting all that together cause some new effects, consequences, that weren’t in the original data collection, and that some other people than those who originally voiced their concerns about the problem would now be worried about? So your data collection component will have to go back to do some more collecting. Each new solution idea will need its own new set of information.
– There goes your orderly systematic procedure all right. That may go on for quite some time, eh?
– Right. Back and forth, if you want to be thorough. ‘Parallel processing’. And it will generate more arguments that will have to be considered, with questions about how plausible the relationship links are, how plausible the concerns about the effects – the desirable / undesirable outcomes. More work. So it will often be shouted down with the usual cries of ‘analysis paralysis’.
Intelligent analysis of data:
Generating ‘new’ arguments?
– Coming to think of it: if our APT has stored all the different claims it has found – in the literature, the textbooks, previous cases, and in the ongoing discussions, would it be able to construct ‘new’ arguments from those? Arguments the actual participants haven’t thought about?
– Interesting idea, Bog-Hubert. – It’s not even too difficult. I actually heard our friend Dexter explain that recently. It would take the common argument patterns – like the ones we looked at – and put claim after claim into them, to see how they fit: all the if-then connections to a proposal claim would generate more arguments for and against the proposal. Start looking at an ‘x’ claim of the proposal. Then search for (‘google’) ‘x→ ?’: any ‘y’s in the data that have been cited as ‘caused by x’. If a ‘y’ you found was expressed somewhere else as ‘desirable or undesirable’ – as a deontic claim, — it makes an instant ‘new’ potential argument. Of course, whether it would work as a ‘pro’ or a ‘con’ argument in some participant’s mind would depend on how that participant feels about the various premises.
– What are you saying, professor? This doesn’t make sense. A ‘pro’ argument is a ‘pro’ argument, and ‘con’ argument is a ‘con’ argument. Now you’re saying it depends on the listener?
– Precisely. I know some people don’t like this. But consider an example. People are discussing a plan P; somebody A makes what he thinks is a ‘pro’ argument: “Let’s do P because P will produce Q; and Q is desirable, isn’t it?” Okay, for A it is a pro argument, no question. Positive plausibility, he assumes, for P→Q as well as for Q; so it would get positive plausibility pl for P. Now for curmudgeon B, who would also like to achieve Q but is adamant that P→Q won’t work, (getting a negative pl) that set of premises would produce a negative pl for P, wouldn’t it? Similarly, for his neighbor C, who would hate for Q to become true, but thinks that P→Q will do just that, that same set of premises also is a ‘con’ argument.
– So what you’re saying is that all the programs out there, that show ‘dialogue maps’ identifying all arguments as pro or con, as they were intended by their authors, are patently ignoring the real nature and effects of arguments?
– I know some people have been shocked – shocked — by these heretical opinions – they have been written up. But I haven’t seen any serious rebuttals; those companies, if they have heard of them have chosen to ignore them. Haven’t changed their evil ways though…
– So our devious APT could be programmed to produce new arguments. More arguments. Just what we need. The arguments can be added to the argument list, but I was going to ask you before: how would the deontic claims, the ‘oughts’, be shown in the model?
– You’d have to add another bubble to each variable bubble, right? Now, we have the variable itself, the value of each variable in the current IS condition, the value of the variable if it’s part of a plan intervention, and the desired value – hey: at what time?
– You had to put the finger on the sore spot, Vodçek. Bad boy. Not only does this make the diagram a lot less clean, simple, and legible. Harder to understand. And showing what somebody means by saying what the solution ought to achieve, when all the variables are changing over time, now becomes a real challenge. Can you realistically expect that a desired variable should stay ‘stable’ at one desired value all the time, after the solution is implemented? Or would people settle for something like: remaining within a range of acceptable values? Or, if a disturbance has occurred, return to a desired value after some reasonably short specified time?
– I see the problem here. Couldn’t the diagram at least show the central desired value, and then let people judge whether a given solution comes close enough to be acceptable?
– Remember that we might be talking about a large number of variables that represent measures of how well all the different concerns have been met by a proposed solution. But if you don’t mind complex diagrams, you could add anything to the systems model. Or you can use several diagrams. Understanding can require some work, not just sudden ‘aha!’ enlightenment.
Certainty about arguments and predictions
Truth, probability, plausibility and relative importance of claims
– And we haven’t even talked about the question of how sure we can be that a solution will actually achieve a desired result.
– I remember our argumentative friends at least claimed to have a way to calculate the plausibility of a plan proposal based on the plausibility of each argument and the weight of relative importance of each deontic, each ought concern. Would that help?
– Wait, Bog-hubert: how does that work, again? Can you give us the short explanation? I know you guys talked about that before, but…
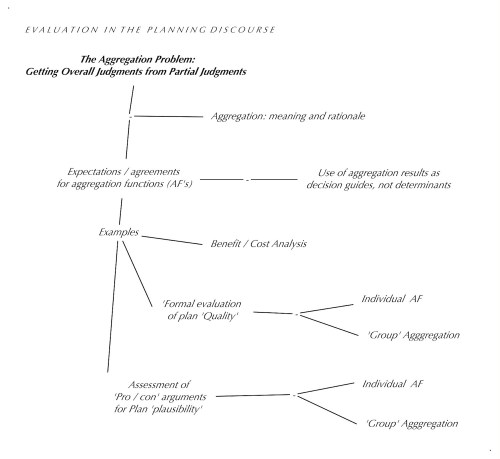
– Okay, Sophie: The idea is this: a person would express how plausible she thinks each of the premises of an argument are. On some plausibility scale of, say +1 which means ‘totally plausible’, to -1 which means ‘totally implausible; with a midpoint zero meaning ‘don’t know, can’t tell’. These plausibility values together will then give you an ‘argument plausibility’ – on the same scale, either by multiplying them or taking the lowest score as the overall result. The weakest link in the chain, remember. Then: multiplying that plausibility with the weight of relative importance of the ought- premise in the argument, which is a value between zero and +1 such that all the weights of all the ‘oughts’ in all the arguments about the proposal will add up to +1. That will give you the ‘argument weight’ of each argument; and all the argument weights together will give you the proposal plausibility – again, on the same scale of +1 to -1, so you’d know what the score means. A value higher than zero means it’s somewhat plausible; a value lower than zero and close to -1 means it’ so implausible that it should not be implemented. But we aren’t saying that this plausibility could be used as the final decision measure.
– Yeah, I remember now. So that would have to be added to the systems model as well?
– Yes, of course – but I have never seen one that does that yet.
‘Goodness’ of solutions
not just plausibility?
– But is that all? I mean: ‘plausibility’ is fine. If there are several proposals to compare: is plausibility the appropriate measure? It doesn’t really tell me how good the plan outcome will be? Even comparing a proposed solution to the current situation: wouldn’t the current situation come up with a higher plausibility — simply because it’s already there?
– You’ve got a point there. Hmm. Let me think. You have just pointed out that both these illustrious approaches – the argumentative model, at last as we have discussed it so far, as well as the systems perspective, for all its glory, have both grievously sidestepped the question of what makes a solution, a systems intervention ‘good’ or bad’. The argument assessment work, because it was just focused on the plausibility of arguments; as the first necessary step that had not been looked at yet. And the systems modeling focusing on the intricacies of the model relations and simulation, leaving the decision and its preparatory evaluation, if any, to the ‘client.’ Fair enough; they are both meritorious efforts, but it leaves both approaches rather incomplete. Not really justifying the claims of being THE ultimate tools to crack the wicked problems of the world. It makes you wonder: why didn’t anybody call the various authors on this?
– But haven’t there long been methods, procedures for people to evaluate to the presumed ‘goodness’ of plans? Why wouldn’t they have been added to either approach?
– They have, just as separate, detached and not really integrated extra techniques. Added, cumbersome complications, because they represent additional effort and preparation, even for small groups. And never even envisaged for large public discussions.
– So would you say there are ways to add the ‘goodness’ evaluation into the mix? We’ve already brought systems and arguments closer together? You say there are already tools for doing that?
– Yes, there are. For example, as part of a ‘formal’ evaluation procedure, you can ask people to explain the basis of their ‘goodness’ judgment about a proposed solution by specifying a ‘criterion function’ that shows how that judgment depends on the values of a system variable. The graph of it looks like this: On one axis it would have positive (‘like’, ‘good’, desirable’) judgment values on the positive side, and ‘dislike’, ‘bad’, ‘undesirable ‘ values on the negative one, with a midpoint of ‘neither good nor bad’ or ‘can’t decide’. And the specific system variable on the other axis, for example that temperature scale from our example a while ago. So by drawing a line in the graph that touches the ‘best possible’ judgment score at the person’s most comfortable temperature, and curves down towards ‘so-so, and down to ‘very bad’ and ultimately ‘intolerable’, couldn’t get worse’, a person could ‘explain’ the ‘objective’, measurable basis of her subjective goodness.
– But that’s just one judgment out of many others she’d have to make about all the other system variables that have been declared ‘deontic’ targets? How would you get to an overall judgment about the whole plan proposal?
– There are ways to ‘aggregate’ all those partial judgments into an overall deliberated judgment. All worked out in the old papers describing the procedure. I can show you that if you want. But that’s not the real problem here – you don’t see it?
– Huh?
The problem of ‘aggregation’
of many different personal, subjective judgments
into group or collective decision guides
– Well, tell me this, professor: would our APTamajig have the APTitude to make all those judgments?
– Sorry, Bog-Hubert: No. Those judgments would be judgments of real persons. The APT machine would have to get those judgments from all the people involved.
– That’s just too complicated. Forget it.
– Well, commissioner, — you’ve been too quiet here all this time – remember: the expectation was to make the decision based on ‘due consideration’ of all concerns. Of everybody affected?
– Yes, of course. Everybody has the right to have his or her concerns considered.
– So wouldn’t ‘knowing and understanding the whole system’ include knowing how everybody affected feels about those concerns? Wasn’t that, in a sense, part of your oath of office, to serve all members of the public to the best of your knowledge and abilities? So now we have a way to express that, you don’t want to know about that because it’s ‘too complicated?
– Cut the poor commissioner some slack: the systems displays would get extremely crowded trying to show all that. And adding all that detail will not really convey much insight.
– It would, professor, if the way that it’s being sidestepped wasn’t actually a little more tricky, almost deceptive. Commissioner, you guys have some systems experts on your staff, don’t you? So where do they get those pristine performance track printouts of their simulation models?
– Ah. Huh. Well, that question never came up.
– But you are very concerned about public opinion, aren’t you? The polls, your user preference surveys?
– Oh, yeah: that’s a different department – the PR staff. Yes, they get the Big Data about public opinions. Doing a terrific job at it too, and we do pay close attention to that.
– But – judging just from the few incidents in which I have been contacted by folks with such surveys – those are just asking general questions, like ‘How important is it to attract new businesses to the city?’ Nobody has ever asked me to do anything like those criterion functions the professor was talking about. So if you’re not getting that: what’s the basis for your staff recommendations about which new plan you should vote for?
– Best current practice: we have those general criteria, like growth rate, local or regional product, the usual economic indicators.
– Well, isn’t that the big problem with those systems models? They have to assume some performance measure to make a recommendation. And that is usually one very general aggregate measure – like the quarterly profit for companies. Or your Gross National Product, for countries. The one all the critics now are attacking, for good reasons, I’d say, — but then they just suggest another big aggregate measure that nobody really can be against – like Gross National Happiness or similar well-intentioned measures. Sustainability. Systemicity. Whatever that means.
– Well, what’s wrong with those? Are you fixin’ to join the climate change denier crowd?
– No, Renfroe. The problem with those measures is that they assume that all issues have been settled, all arguments resolved. But the reality is that people still do have differences of opinions, there will still be costs as well as benefits for all plans, and those are all too often not fairly distributed. The big single measure, whatever it is, only hides the disagreements and the concerns of those who have to bear more of the costs. Getting shafted in the name of overall social benefits.
Alternative criteria to guide decisions?
– So what do you think should be done about that? And what about our poor APT? It sounds like most of the really important stuff is about judgments it isn’t allowed or able to make? Would even a professional planner named APT – ‘Jonathan Beaujardin APT, Ph.D M.WQ, IDC’ — with the same smarts as the machine, not be allowed to make such judgments?
– As a person, an affected and concerned citizen, he’d have the same right as everybody else to express his opinions, and bring them into the process. As a planner, no. Not claiming to judge ‘on behalf’ of citizens – unless they have explicitly directed him to do that, and told him how… But now the good Commissioner says he wouldn’t even need to understand his own basis of judgment, much less make it count in the decision?
– Gee. That really explains a lot.
– Putting it differently: Any machine – or any human planner, for that matter, however much they try to be ‘perfect’ – trying to make those judgments ‘on behalf’ of other people, is not only imperfect but wrong, unless it has somehow obtained knowledge about those feelings about good or bad of others, and has found an acceptable way of reconciling the differences into some overall common ‘goodness’ measure. Some people will argue that there isn’t any such thing: judgments about ‘good or ‘bad’ are individual, subjective judgments; they will differ, there’s no method by which those individual judgments can be aggregated into a ‘group’ judgment that wouldn’t end up taking sides, one way or the other.
– You are a miserable spoilsport, Bog-Hubert. Worse than Abbé Boulah! He probably would say that coming to know good and bad, or rather thinking that you can make meaningful judgments about good or bad IS the original SIN.
– I thought he’s been excommunicated, Vodçek? So does he have any business saying anything like that? Don’t put words in his mouth when he’s not here to spit them back at you. Still, even if Bog-Hubert is right: if that APT is a machine that can process all kinds of information faster and more accurate than humans, isn’t there anything it can do to actually help the planning process?
– Yes, Sophie, I can see a number of things that can be done, and might help.
– Let’s hear it.
– Okay. We were assuming that APT is a kind of half-breed argumentative-systems creature, except we have seen that it can’t make up either new claims nor plausibility nor goodness judgments on its own. It must get them from humans; only then can it use them for things like making new arguments. If it does that, — it may take some bribery to get everybody to make and give those judgments, mind you – it can of course store them, analyze them, and come up with all kinds of statistics about them.
One kind of information I’d find useful would be to find out exactly where people disagree, and how much, and for what reasons. I mean, people argue against a policy for different reasons – one because he doesn’t believe that the policy will be effective in achieving the desired goal – the deontic premise that he agrees with – and the other because she disagrees with the goal.
– I see: Some people disagree with the US health plan they call ‘Obamacare’ because they genuinely think it has some flaws that need correcting, and perhaps with good reasons. But others can’t even name any such flaws and just rail against it, calling it a disaster or a trainwreck etc. because, when you strip away all the reasons they can’t substantiate, simply because it’s Obama’s.
– Are you saying Obama should have called it Romneycare, since it was alleged to be very similar to what Romney did in Massachusetts when he was governor there? Might have gotten some GOP support?
– Let’s not get into that quarrgument here, guys. Not healthy. Stay with the topic. So our APT would be able to identify those differences, and other discourse features that might help decide what to do next – get more information, do some more discussion, another analysis, whatever. But so far, its systems alter ego hasn’t been able to show any of that in the systems model diagram, to make that part of holistic information visible to the other participants in the discourse.
– Wouldn’t that require that it become fully conscious of its own calculations, first?
– Interesting question, Sophie. Conscious. Hmm. Yes: my old car wouldn’t show me a lot of things on the dashboard that were potential problems – whether a tire was slowly going flat or the left rear turn indicator was out – so you could say it wasn’t aware enough, — even ‘conscious?’ — of those things to let me know. The Commissioner’s new car does some of that, I think. Of course my old one could be very much aware but just ornery enough to leave me in the dark about them; we’ll never know, eh?
– Who was complaining about running off the topic road here just a while ago?
– You’re right, Vodçek: sorry. The issue is whether and how the system could produce a useful display of those findings. I don’t think it’s a fundamental problem, just work to do. My guess is that all that would need several different maps or diagrams.
Discourse –based criteria guiding collective decisions?
– So let’s assume that not only all those judgments could be gathered, stored, analyzed and the results displayed in a useful manner. All those individual judgments, the many plausibility and judgment scores and the resulting overall plan plausibility and ‘goodness’ judgments. What’s still open is this: how should those determine or at least guide the overall group’s decision? In a way that makes it visible that all aspects, all concerns were ‘duly considered’, and ending up in a result that does not make some participants feel that their concerns were neglected or ignored, and that the result is – if not ‘the very best we could come up with’ then at least somewhat better than the current situation and not worse for anybody?
– Your list of aspects there already throws out a number of familiar decision-making procedures, my friend. Leaving the decision to authority, which is what the systems folks have cowardly done, working for some corporate client, (who also determines the overall ‘common good’ priorities for a project, that will be understood to rank higher than any individual concerns) – that’s out. Not even pretending to be transparent or connected to the concerns expressed in the elaborate process. Even traditional voting, that has been accepted as the most ‘democratic’ method, for all its flaws. Out. And don’t even mention ‘consensus’ or the facile ‘no objection?‘ version. What could our APT possibly produce that can replace those tools? Do we have any candidate tools?
– If you already concede that ‘optimal’ solutions are unrealistic and we have to make do with ‘not worse – would it make sense to examine possible adaptations to one of the familiar techniques?
– It may come to that if we don’t find anything better – but I’d say let’s look at the possibilities for alternatives in the ideas we just discussed, first? I don’t feel like going through the pros and cons about our current tools. It’s been done.
– Okay, professor: Could our APT develop a performance measure made up of the final scores of the measures we have developed? Say, the overall goodness score modified by the overall plausibility score a plan proposal achieved?
– Sounds promising.
– Hold your horses, folks. It sounds good for individual judgment scores – may even tell a person whether she ought to vote yes or no on a plan – but how would you concoct a group measure from all that – especially in the kind of public asynchronous discourse we have in mind? Where we don’t even know what segment of the whole population is represented by the participants in the discourse and its cumbersome exercises, and how they relate to the whole public populations for the issue at hand?
– Hmm. You got some more of that café catawhatnot, Vodçek?
– Sure – question got you flummoxed?
– Well, looks like we’ll have to think for a while. Think it might help?
– What an extraordinary concept!
– Light your Fundador already, Vodçek, and quit being obnoxious!
– Okay, you guys. Lets examine the options. The idea you mentioned, Bog-Hubert, was to combine the goodness score and the plausibility score for a plan. We could do that for any number of competing plan alternatives, too.
– It was actually an idea I got from Abbé Boulah some time ago. At the time I just didn’t get its significance.
– Abbé Boulah? Let’s drink to his health. So we have the individual scores: the problem is to get some kind of group score from them. The mean – the average – of those scores is one; we discussed the problems with the mean many times here, didn’t we? It obscures the way the scores are distributed on the scale: you get the same result from a bunch of scores tightly grouped around that average as you’d get from two groups of extreme scores at opposite ends of the scale. Can’t see the differences of opinion.
– That can be somewhat improved upon if you calculate the variance – it measures the extent of disagreement among the scores. So if you get two alternatives with the same mean, the one with the lower variance will be the less controversial one. The range is a crude version of the same idea – just take the difference between the highest and the lowest score; the better solution is the one with a smaller range.
– What if there’s only one proposal?
– Well, hmm; I guess you’d have to look at the scores and decide if it’s good enough.
– Let’s go back to what we tried to do – the criteria for the whole effort: wasn’t there something about making sure that nobody ends up in worse shape in the end?
– Brilliant, Sophie – I see what you are suggesting. Look at the lowest scores in the result and check whether they are lower or higher than, than …
– Than what, Bog-Hubert?
– Let me think, let me think. If we had a score for the assessment of the initial condition for everybody (or for the outcome that would occur if the problem isn’t taken care of) then an acceptable solution would simply have to show a higher score than that initial assessment, for everybody. Right? The higher the difference, even something like the average, the better.
– Unusual idea. But if we don’t have the initial score?
– I guess we’d have to set some target threshold for any lowest score – no lower than zero (not good, not bad) or at least a + 0.5 on a +2/-2 goodness scale, for the worst-off participant score? That would be one way to take care of the worst-off affected folks. The better-off people couldn’t complain, because they are doing better, according to their own judgment. And we’d have made sure that the worst-off outcomes aren’t all that bad.
– You’re talking as if ‘we’ or that APT thing is already set up and doing all that. The old Norwegian farmer’s rule says: Don’t sell the hide before the bear is shot! It isn’t that easy though, is it? Wouldn’t we need a whole new department, office, or institution to run those processes for all the plans in a society?
– You have a point there, Vodçek. A new branch of government? Well now that you open that Pandora’s box: yes, there’s something missing in the balance.
– What in three twisters name are you talking about, Bog-Hubert?
– Well, Sophie. We’ve been talking about the pros and cons of plans. In government, I mean the legislative branch that makes the laws, that’s what the parties do, right? Now look at the judicial branch. There, too, they are arguing – prosecutor versus defense attorney – like the parties in the House and Senate. But then there’s a judge and the jury: they are looking at the pros and cons of both sides, and they make the decision. Where is that jury or judge ‘institution’ in the legislature? Both ‘chambers’ are made up of parties, who too often look like they are concerned about gaining or keeping their power, their majority, their seats, more than the quality of their laws. Where’s the jury? The judge? And to top that off: even the Executive is decided by the party, in a roundabout process that looks perfectly designed to blow the thinking cap off every citizen. A spectacle! Plenty of circenses but not enough panem. Worse than old Rome…
– Calm down, Bog-Hubert. Aren’t they going to the judiciary to resolve quarrels about their laws, though?
– Yes, good point. But you realize that the courts can only make decisions based on whether a law complies with the Constitution or prior laws – issues of fact, of legality. Not about the quality, the goodness of the law. What’s missing is just what Vodçek said: another entity that looks at the quality and goodness of the proposed plans and policies, and makes the decisions.
– What would the basis of judgment of such an entity be?
– Well, didn’t we just draw up some possibilities? The concerns are those that have been discussed, by all parties. The criteria that are drawn from all the contributions of the discourse. The party ‘in power’ would only use the criteria of its own arguments, wouldn’t it? Just like they do now… Of course the idea will have to be discussed, thought through, refined. But I say that’s the key missing element in the so-called ‘democratic’ system.
– Abbé Boulah would be proud of you, Bog-Hubert. Perhaps a little concerned, too? Though I’m still not sure how it all would work, for example considering that the humans in the entity or ‘goodness panel’ are also citizens, and thus likely ‘party’. But that applies to the judge and jury system in the judicial as well. Work to do.
– And whatever decision they come up with, that worst-off guy could still complain that it isn’t fair, though?
– Better that 49% of the population peeved and feeling taken advantage of? Commissioner: what do you say?
– Hmmm. That one guy might be easier to buy off than the 49%, yes. But I’m not sure I’d get enough financing for my re-election campaign with these ideas. The money doesn’t come from the worst-off folks, you know…
– Houston, we have a problem …
—

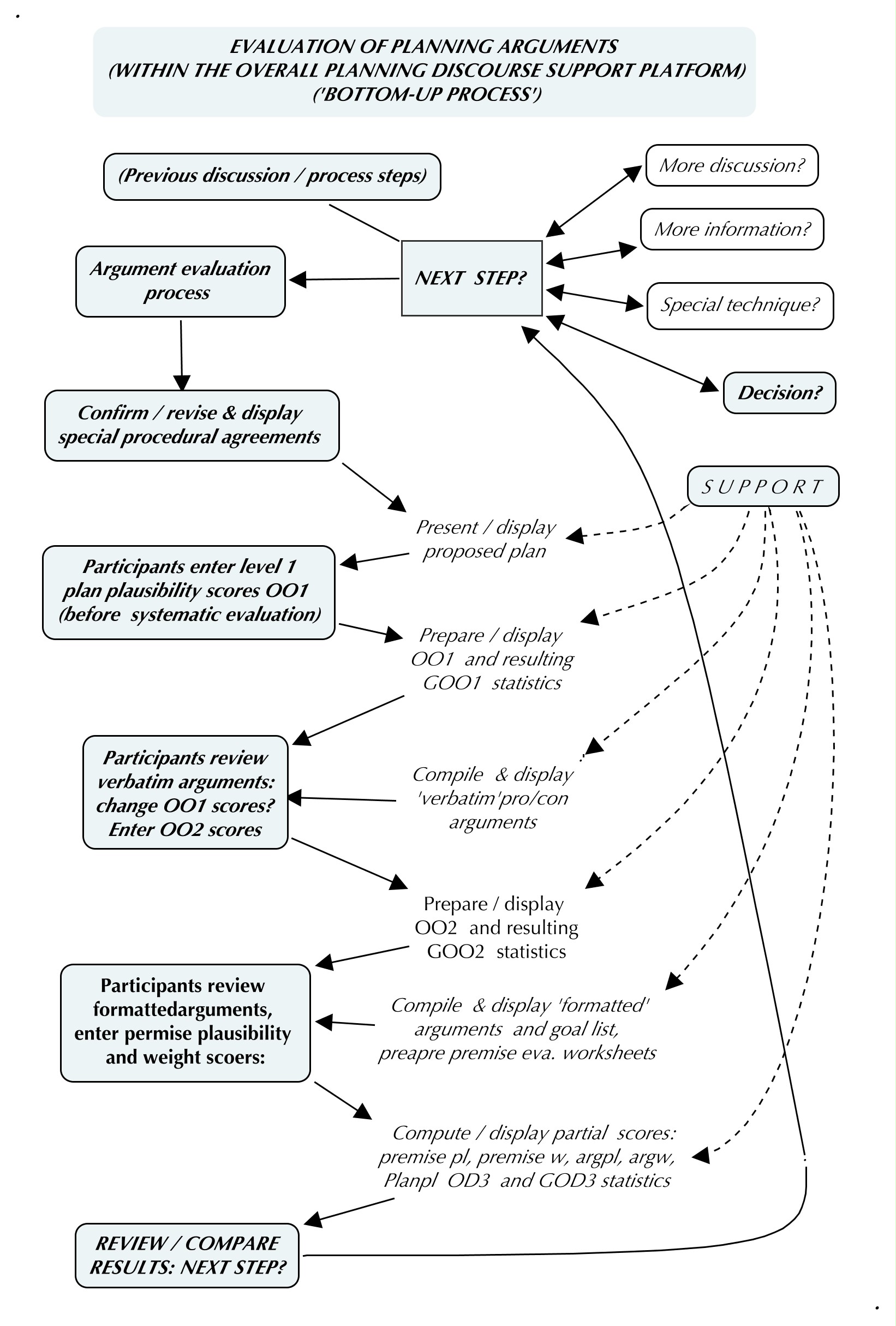
 Evaluation example 1: Steps of a ‘Group Formal Quality Evaluation’
Evaluation example 1: Steps of a ‘Group Formal Quality Evaluation’