An effort to clarify the role of deliberative evaluation in the planning and policy-making process. Thorbjørn Mann, February 2020
TIME AND EVALUATION OF PLANS (Draft, for discussion)
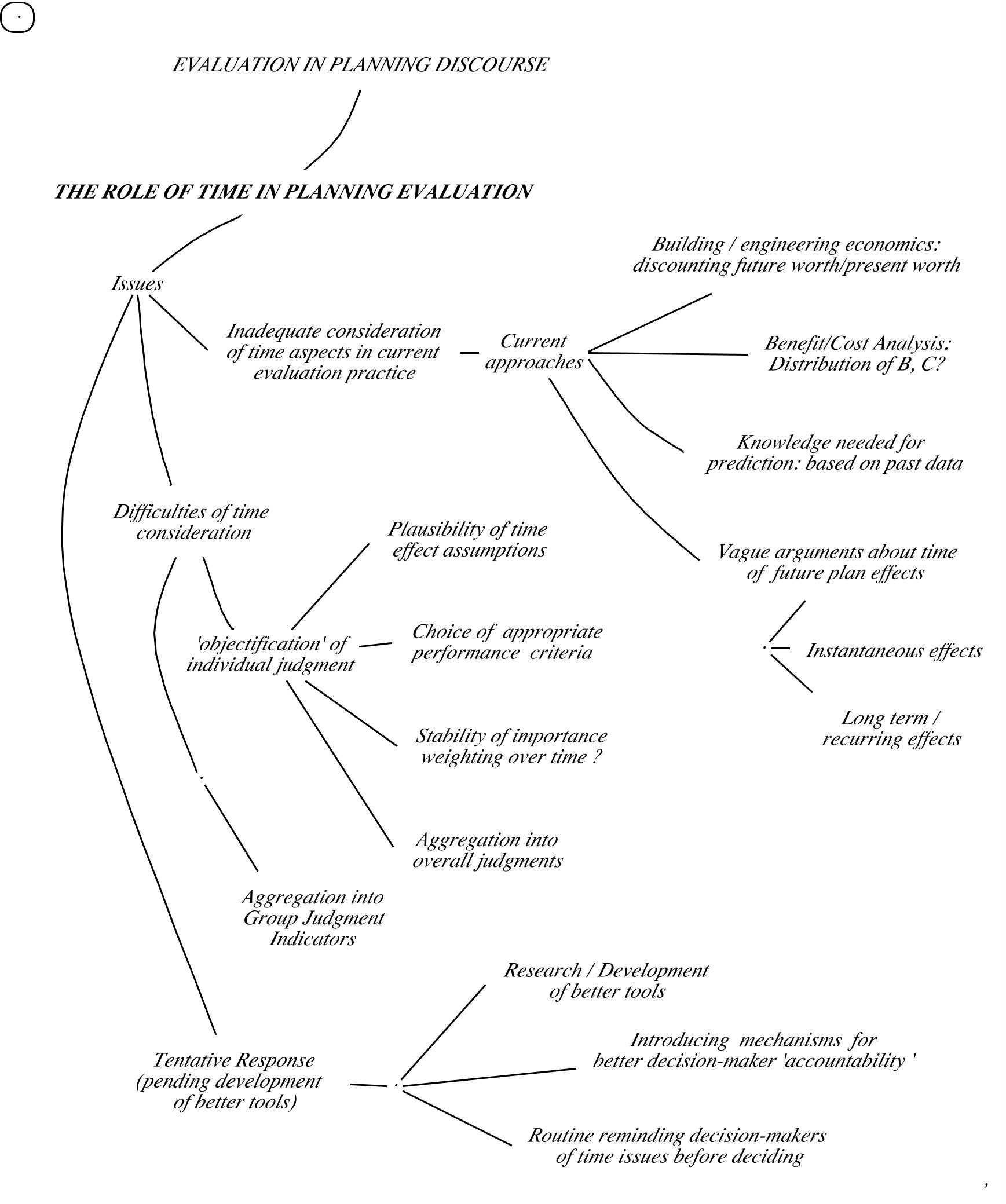
Inadequate attention to time in current common assessment approaches
Considering that evaluation of plans (especially ‘strategic’ plans) and policy proposals, by their very nature are concerned with the future, it is curious that the role of time has not received more attention, even with the development of simulation techniques that aim at tracking the behavior of key variables of systems over many years into the future. The neglect of this question, for example in the education or architects, can be seen in the practice of judging students’ design project presentations on the basis of their drawings and models.
The exceptions — for example in building and engineering economics — are looking at very few performance variables, with quite sophisticated techniques: expected cost of building projects, ‘life cycle cost’, return on investment etc., — to be put into relation to expected revenues and profit. Techniques such as ‘Benefit/Cost Analysis‘, which in its simplest form considers those variables as realized immediately upon implementation, also can apply this kind of analysis to forecasting costs and benefits and comparing them over time by methods for converting initial amounts (of money) to ‘annualized’ or future equivalents, or vice versa.
Criticism of such approaches amount to pointing out problems such as having to convert ‘intangible’ performance aspects (like public health, satisfaction, loss of lives) into money amounts to be compared, (raising serious ethical questions) for entities like nations, where the money amounts drawn from or entering the national budget hide controversies such as inequities in the distribution of the costs and benefits. Looking at the issue from the point of view of other evaluation approaches might at least identify the challenges in the consideration of time in the assessment of plans, and help guide the development of better tools.
A first point to be pointed out is that from the perspective of the formal evaluation process, for example, (See e.g. the previous section on the Musso/Rittel approach), measures like present value of future cost or profit, or benefit-cost ratio must be considered ‘criteria’ (measures of performance) for more general evaluation aspects, for among a set of (goodness) evaluation aspects that each evaluator must be weighted for their relative importance, to make up overall ‘goodness’ or quality judgments. (See the segments on evaluation judgments, criteria and criterion functions, and aggregation.) And as such, the use of these measures as decision criteria must be considered incomplete and inappropriate. However, in those approaches, the time factor is usually not treated with even the attention expressed in the above tools for discounting future costs and benefits to comparable present worth: For example, pro or con arguments in a live verbal discussion about expected economic performance often amount to mere qualitative comparisons or claims like ‘over the budget’ or ‘more expensive in the long run’.
Finally, in approaches such as the Pattern language, (which makes valuable observations about ‘timeless’ quality of built environments, but does not consider explicit evaluation a necessary part of the process of generating such environments), there is no mention or discussion of how time considerations might influence decisions: the quality of designs is guaranteed by having been generated by the use of patterns, but the efforts to describe that quality do not include consideration of effects of solutions over time.
Time aspects calling for attention in planning
Assessments of undesirable present or future states ‘if nothing is done’
The implementation of a plan is expected to bring about changes in the state of affairs that is felt to be ‘problems’ — things not being as they ought to be, or ‘challenges’,‘opportunities’ calling for better, improved states of affairs. Many plans and policies aim at preventing future developments to occur, either as distinctly ‘sudden’ events or development over time. Obviously, the degree of undesirability depends on the expected severity of these developments; they are matters of degree that must be predicted in order for the plan’s effectiveness to be judged.
The knowledge that goes into the estimates of future change comes from experience: observation of the pattern and rate of change in the past, (even if that knowledge is taken to be well enough established to be considered a ‘law’). But not all such change tracks have been well enough observed and recorded in the past, so much estimate and judgment goes into the assumptions already about the changes over time in the past.
Individual assessments of future plan performance
Our forecasts for future changes ‘if nothing is done’, resting on such shaky past knowledge must be considered less that 100% reliable. Should our confidence in the application of that knowledge to estimates of a plan’s future ‘performance‘ then not be be acknowledged as equal (at best) or arguably less certain — expressed as deserving a lower ‘plausibility’ qualifier? This would be expressed, for example, with the pl — plausibility — judgment for the relationship claimed in the factual-instrumental premise of an argument about the desirability of the plan effects: “Plan A will result (by virtue of the law or causal relationship R) in producing effect B”.
This argument should be (but is often not) qualified by adding the assumption ‘given the conditions C under which the relationship R will hold’: the conditions which the third (factual claim) premise of the ‘standard planning argument’ claims is — or will be — ‘given’.
Note: ‘Will be’: since the plan will be implemented in the future, this premise also involves a prediction. And to the extent the condition is not a stable, unchanging one but also a changing, evolving phenomenon, the degree of the desirable or undesirable effect B must be expected to change. And, to make things even more interesting and complex: as explained in the sections on argument assessment and systems modeling: the ‘condition’ is never adequately described by a single variable, but actually represents the evolving state of the entire ‘system’ in which the plan will intervene.
This means that when two people exchange their assumptions and judgments, opinions, about the effectiveness of the plan by citing its effect on B, they may likely have very different degrees (or performance measures in mind, occurring under very different assumptions about both R and C, — at different times.
Things become more fuzzy when the likelihood is considered that the desired or undesired effects are not expected to change things overnight, but gradually, over time. So how should we make evaluation judgments about competing plan alternatives, when, for example, one plan promises rapid improvement soon after implementation, (as measured by one criterion), but then slowing down or even start declining, while the other will improve at a much slower but more consistent rate? A mutually consistent evaluation must be based on agreed-upon measures of performance: measured at what future time? Over what future time period, aka ‘planning horizon’? This question will just apply to the prediction of the performance criterion — what about the plausibility and weight of importance judgments we need to offer complete explanation of our judgment base? Is it enough to apply the same plausibility factor to forecasts of trends decades in the future, as the one we use for near future predictions? As discussed in the segment on criteria, the crisp fine forecast lines we see in simulation printouts are misleading: the line should really be a fuzzy track widening more and more, the farther out in time it extends? Likewise: is it meaningful to use the same weight of relative importance for the assessment of effects at different times?
These considerations apply, so far, only to the explanation of individual judgments, and already show that it would be almost impossible to construct meaningful criterion functions and aggregation functions to get adequately ‘objectified’ overall deliberated judgment scores for individual participants in evaluation procedures.
Aggregation issues for group judgment indicators
The time-assessment difficulties described for individual judgments do not diminish in the task of construction decision guides for groups, based on the results of individual judgment scores. Reminder: to meet the ideal ‘democratic’ expectation that the community decision about a plan should be based on due consideration of ‘all’ concerns expressed by ‘all’ affected parties, the guiding indicator (‘decision guide’ or criterion) should be an appropriate aggregation statistic of all individual overall judgments. The above considerations show, to put it mildly, that it would be difficult enough to aggregate individual judgments into overall judgment scores, but even more so to construct group indicators that are based on the same assumptions about the time qualifiers entering the assessments.
This makes it understandable (but not excusable) why decision-makers in practice tend to either screen out the uncomfortable questions about time in their judgments, or resort to vague ‘goals’ measured by vague criteria to be achieved within arbitrary time periods: “Carbon-emission neutrality by 2050”, for example: How to choose between different plan or policies whose performance simulation forecasts do not promise 100% achievement of the goal, but only ‘approximations’ with different interim performance tracks, at different costs and other side-effects in society? But 2050 is far enough in the future to ensure that none of the decision-makers for today’s plans will be held responsible for today’s decisions…
“Conclusions’ ?
The term ‘conclusion’ is obviously inappropriate if referring to expected answers to the questions discussed. These issues have just been raised, not resolved; which means that more research, experiments, discussion is called for to find better answers and tools. For the time being, the best recommendation that can be drawn from this brief exploration is that the decision-makers for today’s plans should routinely be alerted to these difficulties before making decisions, carry out the ‘objectification’ process for the concerns expressed in the discourse (of course: facilitating discourse with wide participation adequate to the severity of the challenge of the project), and then admit that any high degree of ‘certainty‘ for proposed decisions is not justified. Decisions about ‘wicked problems’ are more like ‘gambles’ for which responsibility, ‘accountability’ must be assumed. If official decision-makers cannot assume that responsibility — as expressed in ‘paying’ for mistaken decisions, should they seek supporters to share that responsibility?
So far, this kind of talk is just that: mere empty talk, since there is at best only the vague and hardly measurable ‘reputation’ available as the ‘account‘ from which ‘payment‘ can be made — in the next election, or in history books. Which does not prevent reckless mistakes in planning decisions: there should be better means for making the concept of ‘accountability’ more meaningful. (Some suggestions for this are sketched in the sections on the use of ‘discourse contribution credit points’ earned by decision-makers or contributed by supporters from their credit point accounts,and made the required form of ‘investment payment’ for decisions.) The needed research and discussion of these issues will have to consider new connections between the factors involved in evaluation for public planning.
Overview
— o —