An effort to clarify the role of deliberative evaluation in the planning and policy-making process
Thorbjørn Mann
OBJECTIVE VERSUS SUBJECTIVE JUDGMENT :
MEASUREMENT VERSUS OPINION
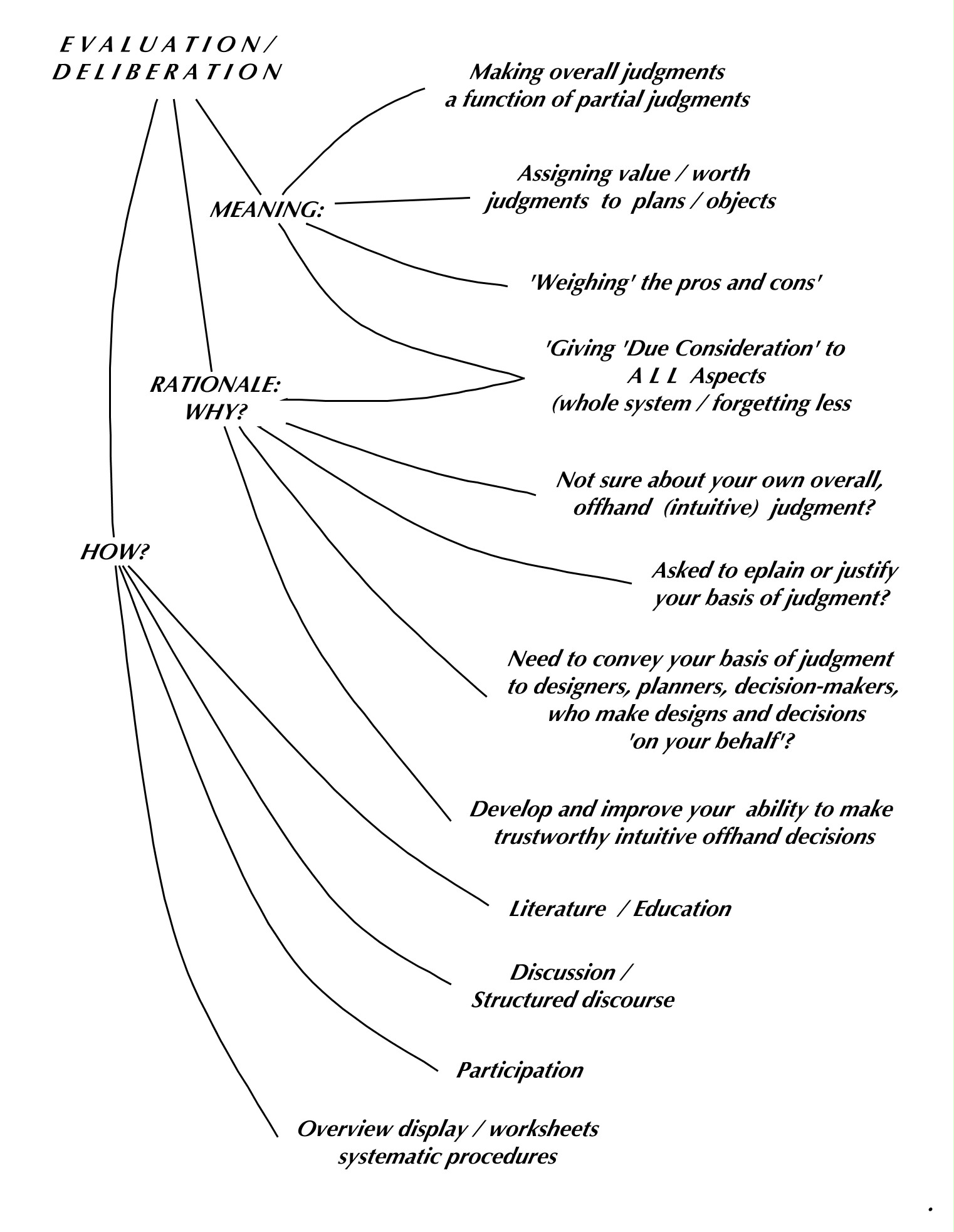
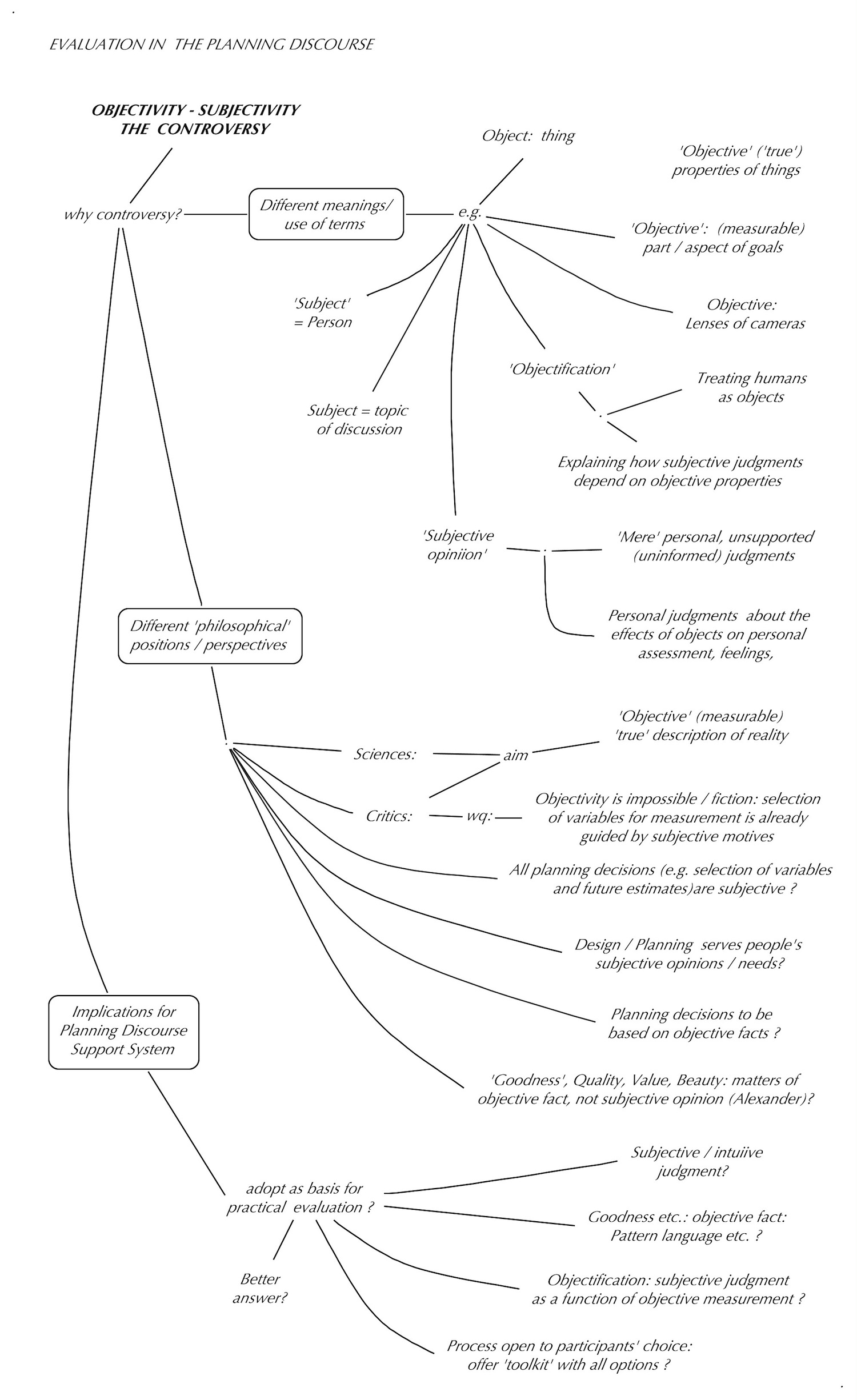
There is a persistent controversy about objective versus subjective evaluation judgments: often expressed as the ‘principle’ of forming decisions based on ‘objective facts’ rather than (‘mere’) subjective opinions. It is also framed in terms of absolute (universal, timeless) values as opposed to relativistic subjective preferences. The desire or quest for absolute, timeless, and universal judgments upon which we ought to base our actions and decisions about plans is an understandable, legitimate and admirable human motivation: Our plans — plans that affect several people, communities — should be ‘good’ in a sense that transcends the temporary and often misguided ‘subjective’ opinions of imperfect individuals. But the opposite view — that individuals are entitled to hold such subjective values (as part of the quest to ‘make a difference’ in their lives) is also held to be even a constitutionally validated human right (the individual right of ‘pursuit of happiness’). The difficulty of how to tell the difference between the two principles and reconcile them in specific situations makes it a controversial issue.
The noble quest of seeking solid ‘facts’ upon which to base decisions leads to the identification of selected ‘objective’ features of plans or objects with their ‘goodness’. Is this a mistake, a fallacy? The selection of those features, from among the many physical features by which objects and plans can be described, is done by individuals. However wise, well-informed, well-intentioned and revered those authorities, does this makes even the selection of features (for which factual certainty can be established), their ‘subjective’ opinions?
Is the jump of deriving factual criteria from the opinions of ‘everybody’, even from the comparison of features of objects from different times as proof of their universal timeless validity, to be considered a mistake or wishful thinking? ‘Everybody’ in practice just means a subset of people, at specific times, in specific context conditions, in surveys mostly separated from situations of actual plans and emergencies and the need for making decisions in the face of many divergent individual judgments.
Regarding ‘timelessness’: the objective fact that the forms and styles of the same category of buildings, (for example, churches and temples, which are expressly intended to convey timeless, universal significance), are changing significantly over time, should be a warning against such attempts of declaring the identity of certain physical properties with the notions of goodness, beauty, awe, wholeness etc. that people feel when perceiving them.
What are the options for participants in a situation like the following?
Two people, A and B, are in a conversation about a plan something they have to decide upon.
They encounter a key claim in the discussion, involving whether an aspect of the plan, that will significantly guide their decision about what to do. The claim is about whether the proposed plan can be said to have certain features that constitute a quality (goodness, or beauty). They find that they both agree that the plan indeed will have those features. But they vehemently disagree about whether that also means that it will have the desired ‘goodness’ quality. An (impartial) observer may point out that in common understanding, the agreement about the plan having those observable features is called an ‘objective’ fact, and that their assessments about the plan’s goodness are ‘subjective‘ opinions. Person A insists that the objective fact of having those objective features implies, as a matter of equally objective fact, also having the desired quality; while B insist that the features do not yet offer the desired experience of perceiving goodness or beauty at all. What are the options they have for dealing with this obstacle?
a) A attempts to persuade B that the features in question that constitute quality are part of a valid theory, and that this should compel B to accept the plan regardless of the latter’s feeling about the matter. The effort might involve subtle or not-so-subtle application or invocation of authority, power, experience, or in the extreme, of labeling B a member of undesirable categories: (‘calling B names’): an ignorant follower of disreputable ‘isms’, insensitive, tasteless beings unable to perceive true quality, even conscious or subconscious shameful pursuits not letting him (B) admit the truth. Of course, in response, B can do this, too…
b) B can attempt to find other features that A will accept (as part of A’s theory, or an alternate theory) that will generate the feeling of experiencing quality, but let A continue to call this a matter of objective fact, and B calling it subjective opinion. This may also involve B’s invoking compelling factors that have nothing to do with the plan’s validity or quality, but e.g. with a person’s ‘right’ to their judgment, or past injustices committed by A’s group against B’s tribe, etc.
c) They can decide to drop the issue of objective versus subjective judgments as determinants of the decision, and try to modify the plan to contain features that will contain both the features A requires to satisfy the theory, and B’s subjective feelings. This usually requires making compromises, one or both parties backing off from the complete satisfaction of their wishes.
d) They could call in a ‘referee’ or authority, to make a decision they will accept for the sake of getting something — anything,– done, without either A or B having to actually change their mind.
e) They can of course abandon the plan altogether, because of their inability to reach common ground.
There does not seem to be an easy answer to this problem that would fit all situations. Seen from the point of view of planning argumentation, where there is an attempt to clearly distinguish between claims (premises of arguments) and their plausibility assessment: is the claim of objectivity of certain judgment an attempt to get everybody to assign high plausibility values to those claims because of their ‘objectivity’?
Stating such claims as planning arguments make it easier to see that theories claiming desirable quality-like features to be implied by must-have objective properties show the different potential sources of disagreements. In an argument like the following, A (from the above example) claims: The plan should have property (feature) f, because f will impart quality q to the plan, given conditions c, which are assumed to be present . The ‘complete’ argument separating the unspoken premises is:
D: The Plan should include feature f (‘Conclusion’)
because
1) FI (f –> q) (if f, then q) (Factual – instrumental premise)
and
2) D(q) (Deontic premise)
and
3) F(c) (Factual premise)
Adherent A, of a theory stating postulates like “quality q is generated by feature f, and that this is a matter of objective fact” — may be pointing to the first and third premises that arguably involve ‘factual’ matters. Participant B may disagree with the argument if B thinks (subjectively) that one or several of the premises are not plausible. B may even agree with all three premises — with an understanding that f is just one of several or many ways of creating plans with quality q. Thus, B will still disagree with the ‘conclusion’ because there are reasons — consequences — to refrain from f, and look for different means to achieve q in the plan. This is a different interpretation of the factual-instrumental premises: A seems to hold that premise 1 actually should be understood as “if and only if f, then q”. (The discussion of planning arguments thus should be amended to make this difference clear.) Does the theory involve a logical fallacy by jumping from the plausible observation that both premises 1 and 3 involve ‘objective’ matters, to the inference “iff f then q”? Such a theory gets itself into some trouble because of the implication of that claim: “if not-f then not q”? A proponent of Alexander’s theory (1) seems to have fallen to this fallacy by claiming that because the shape of an egg does not meet some criteria for something having beauty according to this theory, the egg shape cannot be considered to be beautiful. Which did not sit well even with other adherents to the basic underlying theory.
The more general question is: Must this issue be addressed in the ‘procedural agreements’ at the outset of a public planning project? And if so: how? What role does it play in the various evaluation activities throughout the planning process?
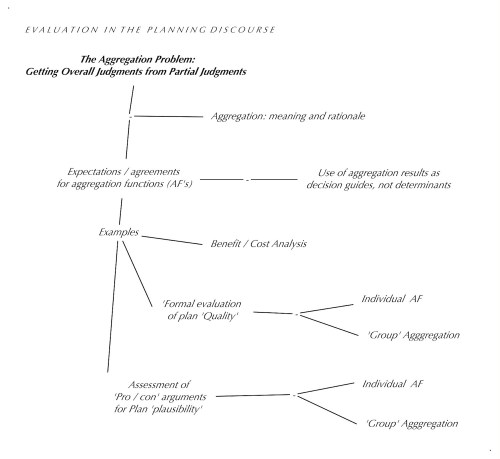
One somewhat facile answer might be: If the planning process includes adequate public participation — that is, all members of the public, or at least all affected parties, are taking part in it, including the decisions whether to adopt the plan for implementation — all participants would make their own judgments, and the question would just become the task of agreeing on the appropriate aggregation function (see the section on aggregation) for deriving an overall ‘group’ decision from all individual judgments. If this sounds too controversial, the current practice of majority voting (which is one such aggregation function, albeit a problematic one) should be kept in mind: it is accepted without much question as ‘the way it’s done’. Of course, it just conveniently sidesteps the controversy.
Looking at the issue more closely, things will become more complicated. For one, there are evaluation activities involved in all phases of the planning process, from raising the issue or problem, searching for and interpreting pertinent information, writing the specifications or ‘program’ for the designers to develop ‘solution’ proposals, to making a final decision. Even in the most ambitious participative planning processes, there will be very different parties making key decisions in these phases. So the question becomes: how will the decisions of ‘programming’ and designing (solution development) impact the outcome, if the decision-makers in these early phases are adherents of a theory that admits only certain ‘objective’ features as valid components of solution proposals, and ignores and rejects concerns stated as ‘subjective opinions’ by affected parties? So that the ‘solutions’ the ‘whole community’ is allowed to participate in accepting or rejecting are just not reflecting those ‘subjective’ concerns?
For the time being, one preliminary conclusion drawn here from these observations may be the following: Different expressions and judgments about whether decisions are based on timeless, universal and absolute value considerations or ‘subjective opinions‘ must be expected and accommodated in public planning, besides ‘objective’ factual information. Is it one of the tasks of designing platforms and procedures to do that, to find ways of reaching agreement about practical reconciliation of these opinions? Is one first important step towards that goal the design and development of better ways to communicate about our subjective judgments and about how they relate to physical, ‘objectively measurable’ features? This question is both a justification for the need for deliberative evaluation in collective planning and policy-making, and one of its key challenges.
These are of course only some first draft thoughts about the controversy that has generated much literature, but has not yet been brought to a practical resolution that can more convincingly guide the design of a participatory online public planning discourse platform. More discussion seems to be urgently needed.
Note 1): Bin Jiang in a FB discussion about Christopher Alexander’s theory as expressed in his books: e.g. ‘A Pattern Language’ and ‘The Nature of Order’
–o–



 –o–
–o–