A question posted (on the LI systems thinking network) asked whether anybody had seen a documented Causal Loop Diagram of ‘virtuous loops’ systems in systems. Did it imply that there arent any? I suggested that the provision of merit point rewards for participation in public planning discourse,and the subsequent use of those points to make public officials ‘pay’ for power decisions that have not been publicly discussed, contained at least one such virtuous loop. Because I hadn’t also provided a CLD in the standard format, this was roundly rejected. It is not clear to me whether this was because of the lack of a CLD, or whether the entire discourse process envisioned (but not described in complete detail) does not qualify as a system, in the author’s opinion. Other comments seemed to support this interpretation. For me, this raised some questions about the concept of ‘system’, its definition link or restriction to Causal loop phenomena, and their usefulness for the design of such projects as the discourse support platform.
The proposed ‘Public Planning Discourse Support Playtform’ I sometimes called a ‘system’ can be seen and described in several different ways.
To see what physical framework items for a discourse are involved , it may be useful to first look at a discourse taking place in a real physical space with human participants communicating vocally about a problem or idea calling for a plan to implement it.
The human participants, assembled in response to a call for discussion of a problem or idea or plan. proposed a plan whose realization wil require approval and resources by the community: This may be spoken or shouted out or displayed as a (deontic) question:
“Should (‘ought’) Plan A be adopted for implementation?”
If the proponent is not an official (leader, designated or usurped ‘dictator’, simply announcing their intent to compel the community to adopt the plan, their aim is to obtain a (set of) acceptance message(s)— a ‘decision’ from the community signaling that “Yes, Plan A ought to be adopted.” One or more reasons may suggest that this should first be discussed; that ‘pros and cons’ should be considered. The set of activities, and rules guiding their sequence to result in a final decision is a process. According to some understanding of ‘system’ — a set of ‘items’ with relationships between them — is it also a system?
There are several definitions of ‘system’ in the systems domain, such as the ‘stock and flow’ concept, or the view that a system is a set of (preferably measurable) variables related by cause-effect relationships; described by ‘causal loop diagrams’ — implying a condition I have read that such a thing must have ‘loops’ in order to quality as a system; or more elaborate views such as that ‘“system paths are characterized with nodes that represent unique centers of inter unitary relationships conveying enabling communication for both internal systems and the whole system of systems”.
There are aspects of the platform project that can meet several such definitions, by focuisng on different aspects. For example, the physical ‘containers’ and displays needed to proccess the flow of messages, and their connections, that may be primitive to the point of dismissal in town hall meetings, but becoming a distinct design problem as soon as the process is taken ‘online’. The professionals involved in its construction and operation will call this a ‘system’.
A different view may focus on the content of the messages exchanged. In addition to the different types of claims about the merit of the proposed plan, the participants will harbor and express judgments about its desirability or plausibility. The judgments can be expressed as characterizations such as ‘nonsense’ or ‘brilliant’ or ‘gee, I don’t know’, (which are not very helpful in assessing a collective ‘judgment’), or on a better defined scale. For example, one with the values ‘yes, don’t know, no’, or a more detailed one such as numbers ranging from +1 (meaning definitely yes), totally plausible) via 0 (don’t know, can’t decide) to -1 (definitely not, totally implausible) with degrees of plausibility in-between. The messages exchanged between participants (pros and cons, for example) serve to decrease or increase the individual overall plan plausibility judgments. The pros and cons can be further ‘explained’ (justified or supported) by further arguments in favor of the premises of the pros and cons, and on their plausibility. From such individual judgments, some form of statistical aggregation into a ‘community decision judgment’ on the same scale can be formed to guide the decision.
This, like the physical components ‘system’, sounds more like a ‘stock and flow’ kind of process, but I’m not sure whether there are loops in those flows to make it a proper system, and whether this is a key concern to worry about. Possibly if the process provides the option of modifications of the originally proposed plan in response to arguments: Certain changes will result in increase in judgments about some aspects while reducing others. The process will then become more complicated (and may often appear to some as too complex and even chaotic, even returning to ‘physical’ in a different sense).
Curiously, the scant efforts to improve this phenomenon seems to appear too complex for many who prefer to rely on simple ‘yes/no’ majority voting regardless of the problems and ‘chaotification’ associated with this crude method (voting rights, the various forms of ‘rigging the system’ (if it indeed Is one); the complex process of drawing complex shapes of voting districts known as ‘gerrymandering’, and its blatant disregard for the solemnly invoked principle of ‘due consideration of all pros and cons’ about public plans: the wholesale dismissal of the concerns of the voting minority.
’Reaching across the aisle’ to the miscreants and sinners?: Treason.
Whether this represents just the inevitable minor aberrations of the supreme governance model of ‘democracy’ or forboding its demise may be worth a separate discussion.
The upshot of these musings? The issue of whether or not, or on what conditions, the project can be called a ‘system’ is, in my modified judgment, not very helpful, in spite of the initially inspiring notion of guiding its design by providing it with ‘virtual’ loops towards better planning decisions. It also seems to indicate that single forms of ‘systems’ models — cause-effect, stock and flows, only apply well to selected aspects of the overall project. Is it then composed of several such systems, or asre the systems models just inadequate tools for the description of the whole thing? Again: is that issue helpful or a distraction to its design?
It seems that i must regretfully leave the systems community to ponder its own process of evolving into a collection of systems silos with its arrays of admission criteria, and abstain from using the term ‘system’ altogether. So what should I call it?
Another new, evil bugaboo if not just one more disguise or reincarnation of ‘socialist’, ‘neoliberalist’, but essentially authoritarian tyrnanny schemes?
I happened lo listen to a lecture urging resistance against the WEF-driven ‘Great Reset’ that is using humanitarian crises like the Covid-pandemic as levers for unprecedented transitions toward capitalist-state-controlled Big Brother tyranny. Using well-intentionet benevolent mass protection directives (or means that can be presented as necessary mass protection tools, like wearing facemasks, social distancing, vaccination) as opportuntities for getting people used to more freedom-destroying oppression. Getting strong impressions that these warnings and concerns are either perhaps well-intentioned but based on thoroughly misunderstood misrepresented nature and causes of the attacked evils, or just political ‘propaganda’ messages against the current administration — the very thing they accuse
Assuming for a moment the interpretation of well-intentioned misunderstanding, but getting the direction of forces wrong: Some key considerations. (Numbered for conveninece in responding, not to indicate any order of importance)
1. Must not ANY initiative for improvement — well-intentioned or equally just power-hungry for the sake of power — pursue some degree of POWER (‘empowerment’) to spread its ideas and get them adopted? Which also applies to any initiatives for resisting such initatives?
2. Must not ANY adoption of ‘new’, ‘innovative’ or ‘restoring’ (repairing, returning to previous good states) initiatives and provisions at governance level (requiring adherence by all members of a community) run up against some degree of RESISTANCE by ‘opposition’ groups perceiving loss of status, power, well-being, profit from the change?
3. Must not such opposition be expected, the more DECISIONS for adoption have been reached by decision methods that inadvertently or deliberately ignore or override the concerns of such segments of society, now feeling disadvantaged? Decision modes such as ‘leadership’ dictates or even majority voting, no matter how well justified as the very essence of democracy?
4. Are not most if not all current governance tools aiming at common ADHERENCE to agreements (‘laws’) even by disavantaged parties, based on the notion of ‘ENFORCEMENT’ —that is, punishing violations by force (implied in the very term ‘enforcement’) or threat of force?
5. Will such opposition resistance not have to seek and adopt reciprocal force against ‘law enforcement’ means — the more so, the more the very decision modes for law adoption prevent or distort or ignore other means of expressions of concerns by the disadvantaged parties? (Does this not include the ‘propaganda’ means of reckless mutual disputing / misrepresenting the intelligence, honesty, civil-mindedness, ethics, patriotism etc.?)
6. Will this reliance on force and counter-force not lead to a continuing escalation of the tools (weaponry) of ‘enforcement’ and ‘resistance’? Escalation that can lead to internal civil war and revolution, and, given the increasing destructiveness of modern weaponry, utterly ‘MAD’ outcomes on the larger, international level?
7. Do these mechanisms not, potentially, apply to ALL historical and current forms of governance — not just to ‘socialist’ or ‘facist’, ‘chinese communist’ or ‘chinese capitalist’ but also to the ‘democratic’ regimes that are increasingly bought by the big corporations and oligarchs, or taken over by the military? The common denominator being the LACK OF EFFECTIVE CONTROLS OF POWER?
Note that this conclusion does not imply nor justify the wholesale rejection of power: there are many situations in which effective public decisions will have to be made ‘fast’, without the benefit of thorough public discourse: On a ship encounering an iceberg in the ocean, one decision must be made ‘fast’ — pass the iceberg on the port or starboard side, with all necessary intemediate means for adopting the new course being followed by all affecte members of the crew?
8. Regardless of the answers to these questions, does criticism of current ways of doing things not imply some responsibility of engaging in and encouraging a better PUBLIC DISCOURSE, supporting, even requiring, efforts of developing and discussing alternative, better ways? Should mere complaints and attacks on ongoing or proposed change, without concrete suggestions of better ways to deal with the problems, just be seen as political ‘propaganda’ in the interest of gaining politicsal power but under the same basic conditions that generated the problems?
9. It would be presumptuous and preposterous for any single person to claim to have all the answers. It can be argued, instead, that as a collective species, the global humanity as much as smaller local communities, WE DO NOT HAVE A CONVINCING, UNIVERSALLY ACCEPTABLE MODEL FOR SURVIVAL – YET. It could even be argued that humans are a designing, planning species with every generation wanting to develop its own ‘NEW’ definition, vision, design, plan for what it means to be human, and that it should be ‘empowered’ to do so, and that any ultimate ‘RESET’ model would be the wrong answer.
So my own attempts to offer some thoughts should be seen as efforts to respond to that responsibility of #8 above as encouragements to develop, engage in, and offering initial contributions and proposals to the necessary public discourse, not as any ultimate panacea: Some urgently needed considerations and efforts:
10. There are many efforts, theories, initiatives, experiments and proposed ‘models’ already being developed and implemented all over the world. They are diverse, not all agreeing on the same principles and assumptions, and arguably not communicating well either with similar initiatives or a wider public. However: should they not be encouraged and supported, by a global community? Perhaps on some conditions: of
10.1 Remaining ‘local’ (in the sense of respecting, tolerating neighboring and existing systems — until common larger, even global agreemenrts have been achieved by satisfactory and peaceful means;
10.2 Comprehensibly sharing their ideas and experiences (sucesses, obstacles, and failures) as well as proposals for wider adoption in a global repository for mutual learning, discussion and evaluation;
10.3 Refraining from any form of violent, deceitful, or otherwise coercive attempts to impose their provisions on other parties.
11 Encouraging the development of a ‘PUBLIC PLANNING DISCOURSE SUPPORT PLATFORM’ both to house and facilitate access to the respository of innovation / restoration initiatives, and the discussion of necessary ‘global’ agreements (common ‘road rules’ akin to the decision to dirve on the right or left side of the road…)
12 Development of a PUBLIC (potentially global as well as ‘local’) PLANNING DISCOURSE SUPPORT PLATFORM aiming at common decisions based on the quality and merit of information and contributions to the discourse, containing:
12.1 INCENTIVES for wide and speedy public participation;
12.2 Standard INFORMATION SUPPORT (Similar incentives, reaearch etc.)
12.3 TECHNIQUES AND PROCEDURES for structured discourse without excessive repetition, disruptive and flawed contributions but concise, effective overview of the whole spectrum of contributions;
12.4 Optional provisions for SYSTEMATIC EVALUATION of contribution merit (e.g. the merit or proposals or proposal improvement ideas, or of arguments pro or con proposals);
12.5 Development and provisions for DECISION-MAKING (Recommendations, agreements) based on contribution merit (rather than on shortcuts such as majority voting which systematically disregards minority concerns, and in itself is inapplicable to projects and problems transgressing traditional the boundaries of governance entities where the numbers of voters can be meaningfully defined…)
13 Development of NEW tools for ENSURING ADHERENCE of desisions and agreements, as much as possible based on automatic prevention of violations (triggered by the very attempt of violation) rather than violent or coercive ‘enforcement’.
14 Development of better provisions for the CONTROL OF POWER, aiming at preventing the escalation of power and power tools and the corresponding intesity of opposition.
Tentative ideas for innovative techniques and tools related to the above items 10, 11, 12, 13, and 14 have been proposed for discussion in my papers on Academia.edu, FB, LI, books, and Abbeboulah.com blog; pfd files can be sent by email to interested people upon request (by LI message).
Picking up a cup of coffee at the counter in the coffee shop, the old man went out on the deck under the large oak tree, briefly enjoying the view – the park, the walkway along the shore of the little lake. Habit, for many years now. Looking for an empty seat at a small table, — not the large round one where there used to be conversation between the regular customers. There was no such conversation anymore. The old friends and acquaintances had disappeared. Some had died, others had given up on conversation for the same reasons he did not even expect it now: his failing hearing that even hearing aids could not assist: they only delivered more noise but no understanding. Most of the tables were occupied by studious-looking people — all younger — laptops or cellphones diverting their attention even from the arrival of new customers. But his habit kept him coming back He picked a seat with some sun, — it was still early spring, with a chill breeze — and a view of the lake. His little notebook and the four-color pen at the ready for any insights that might occur to him, about various ideas and projects he was still ‘working’ on, that might perhaps, one day, turn into a book.
No new ideas came to him today. Instead, curious memories of events he had thought were long forgotten. One, in particular, kept him reflecting about how the most innocent little incidents, — pranks, jokes,– sometimes had unexpected larger consequences. Interfering in others’ plans and strategies in ways that even the most thorough efforts at anticipating forces that might help or interfere would not have been able to conceive or foresee.
One such incident involved a prank from his school days — a secondary education institution in a mid-size town. Its principal had the curious habit of sending out brief memoranda with announcements or new rules he kept inventing or reminding his students and faculty about. Such as invoking, at the first snowfall, the stern prohibition of snowball fights in the courtyard.
These memoranda were always typed (this was long before computers or even electric typewriters) on a single sheet of cheap newsprint paper. On the bottom, there was a stamp — like the old office rubber stamps that showed the sender’s address or read ‘copy’ or ‘file’ — that listed all the classes by level and number, and a space for the instructor’s initials to sign off after they had been read out in the respective class. This stamp was unusual in that it had a wonderful violet hue ranging unevenly from blue to red — evidently, because the secretaries having typed the messages randomly used a blue or red stamp pad, whichever happened to be closer at hand. The ritual was for the first teacher to come by the secretary’s desk on his way to his next class, to pick up the memo, read it to the students, and then send a student to take it to the next class, and so forth, until every class had been duly notified.
It so happened that one such memo had been left in the class of the old reveler in ancient memories, The last one that day, of no further use. One student was intrigued by the graphical uniqueness of the stamp, and had an idea of an unusual prank: what if such memo could be constructed on a similar-looking paper, with some ridiculous but sufficiently plausible new rules to fool at least some instructors into reading it in their classes, and perhaps cause some confusion? The very uniqueness of the memo, the stamp, the paper, the old typewriter font, made it a challenge. But it also ensured, if successfully forged, would make any strange message seem quite in line with the principal’s unusual communication habit, that seemed to serve some need to remind everybody of his position of power.
The challenge led to a conspiracy by a small group of students, that turned out surprisingly successful. A matching sheet of typewriter paper, slightly yellowed like the original, was found; as well as a parent who owned an old typewriter with the same font. The two or three conspirators had a lot of fun concocting plausible-sounding messages, and settled on three or four. He only remembered two: One referred to the usual chaos of the area where students using bicycles were allowed to store them. The message declared that only students who could prove that they lived a certain distance from the school would receive a permit card to store their conveyance in that place in an orderly fashion on penalty of losing the permit. They would be able to pick up such cards in the chart storage room where the rolled up maps of the Roam Empire, the pictures of mammals, fishes, birds and of course the map of the country as well as that of city were stored. A geography teacher or a janitor would be there, to check the distance on the city map before issuing the permit.
Another new rule involved the grand central staircase of the school’s four-story building. It was an elaborate affair, with a first broad run going from the main corridor up to a landing, from which there were two further runs, one to the right, one to the left — returning to the central hallway at the next level. At the bell ringing for breaks, this stair was often the venue of confusion and even collisions between students running up or down in different directions. So the memo declared succinctly that from now on, there would be a strict right-hand traffic: going up on the right side of the main central run, and using the right-hand upper run; and going down on the opposite run and then the ‘left’ side (seen from below). The old man could not remember the third and fourth message, to his consternation —though he had actually been one of their collaborative authors, but he satisfied himself thateven remembering the two was a good sign, considering his advanced age.
The forgery of the stamp, he did remember well, however, was the masterpiece of the plot. Evidently, no stamp with the classroom pattern was available, nor could two adequately faded red and blue stamp pads be found. It was achieved with a fine-point calligraphy pen dipped in watercolor of the varying blue-to-red colors, letter by letter, and took some time and patience on the part of a student who had good grades in art class. He wistfully regretted that no grade would be given for this homework. The result was indistinguishable from the original, at the expected cursory sight by the teachers. A sloppy pair of initials resembling a hastily written ’47’ more than a faculty signature (to protect any of the faculty from suspicion of being the author) was scrawled on one of the class check-off spaces, indicating that it had already been read there.
It remained to get the memorandum into proper circulation. None of the conspirators were seated close to the door, but fortunately, a new student who had rcently been transferred from another school had been assigned to that (otherwise undesirable) seat. Being new and needing to gain respect and acceptance in this new tribe, he could be persuaded into taking the memo, and at the call from one or two of the conspirators that ‘someone knocked on the door’ would jump up to open the door, and then hand the memo to the teacher. Accompanied by some other random noise, the call came as soon at the teacher had ventured far enough from the door, the hand-over was performed without raising suspicion. The message was read — any chuckles from students were common enough at such readings and did not alert that teacher to anything unusual, and the memo was sent to another class without incident.
The next break revealed the unexpected great success. There was a line in front of the chart storage room — but no teacher was there to issue bike permit cards. At the staircase, however, one faculty member had taken it upon himself to direct the traffic, loudly hollering “Righthand traffic!” — to the consternation of other students and faculty who had not gotten the news: it turned out that after a few successful proclamations, the memo had arrived in a class taught by the principal himself, who confiscated it, visibly shaken by some emotion that students could not identlify. The new, peaceful traffic pattern had just taken hold when the principal interferred to cancel the new rule.
No further mention nor efforts at implementation of the new policies came to the attention of the conspirators; after a few days, it seemed that the incident had just been forgotten.
However, several weeks later, a few students had gone to a new public sauna outfit in town, that had announced a special promotion student discount on Thursday afternoons. It so happened that there also was a group of distinguished (by corpulence) men sweating away in the same hot venue, who turned out to be members of the liberal party in the city council of that town. And they were discussing a crisis that had arisen in the very school — which was under the jurisdiction of the city. It seemed that a vicious struggle had arisen between the principal’s effort to get one particular faculty member fired, whom he suspected of having launched a forged memo to the school (for unclear purposes other than self-promotion); and that faculty member who accused the principal of having lost control and confidence of the faculty. It was known that this very faculty member himself had previously insinuated ineffectiveness on the part of the principal, and made no effort to hide his own aspiration to that post. As luck — bad or otherwise — would have it, it was also the same teacher who had so impressively directed the new traffic pattern in the staircase. But he vehemently insisted that accusing him of the authorship of that memo was just a lurid part of the principal’s own efforts to denigrate and discredit him so as to get him fired and removed as a competitor for the position.
The poor city council members seemed at a loss about what to do about this affair. The discussion in the hot room got hot — it seemed that there also were issues about party affiliations involved — but had to be discontinued for the group to get into the ice cold pool to cool off. So there was no opportunity, if there had even been an effort on the part of the students, to enlighten the council members to the naked truth of the matter — that they were looking at the very authors of the infamous memo.
There was no indication as to whether and how that crisis had been resolved — neither one of the suspected/accused parties were fired from their respective positions, at least for some time after that incident. And the old man had lost track of any further developments, since his family moved to another city soon afterwards and he had enrolled in a different school.
But he could not resist a secret chuckle at the memory of the incident. And he resolved to use it in his social network activity to remind his social network systems thinking friends of the unpredictability of spurious context interference into social systems behavior patterns and change strategies.
Last update: 4/5/2022 (Adding section 10 on Evaluating Discoures Contributions)
Thorbjørn Mann
I submit, for discussion, that better controls of power are desperately needed, as are public (global) decision-making tools that better — that is, more transparently — link the merit of discourse contributions with the decisions, and that the development of a better discourse platform with some provisions for evaluation of contributions can offer both:
1 THE URGENT NEED FOR PUBLIC (GLOBAL?) PLANNING DISCOURSE PLATFORM , DECISIONS BASED ON DISCOURSE CONTRIBUTION MERIT, AND
CONTROL OF POWER
Tall order: I agree, and I expect that many will find it impossible, if only because it looks too complex. Plausible — but is it reasonable to expect that complex problems can be ‘fixed’ with simple tricks? Some potential provisions I have found while working on improvements to planning decision-making suggest to me that better tools for both the discourse decision-making and the power control issue are possible, and that they should be discussed, as well as that the search for other, better answers should be pursued more intensively than what I currently see.
To support my perhaps naively optimistic hypothesis but also to invite critical comments and better ideas, I suggest to break up the discussion into ‘chunks’ that can be discussed in more depth; the effort to present the whole ‘system’ in its overall complexity has always led to larger, even book-size articles whose very size discourage discussion if they even get read.
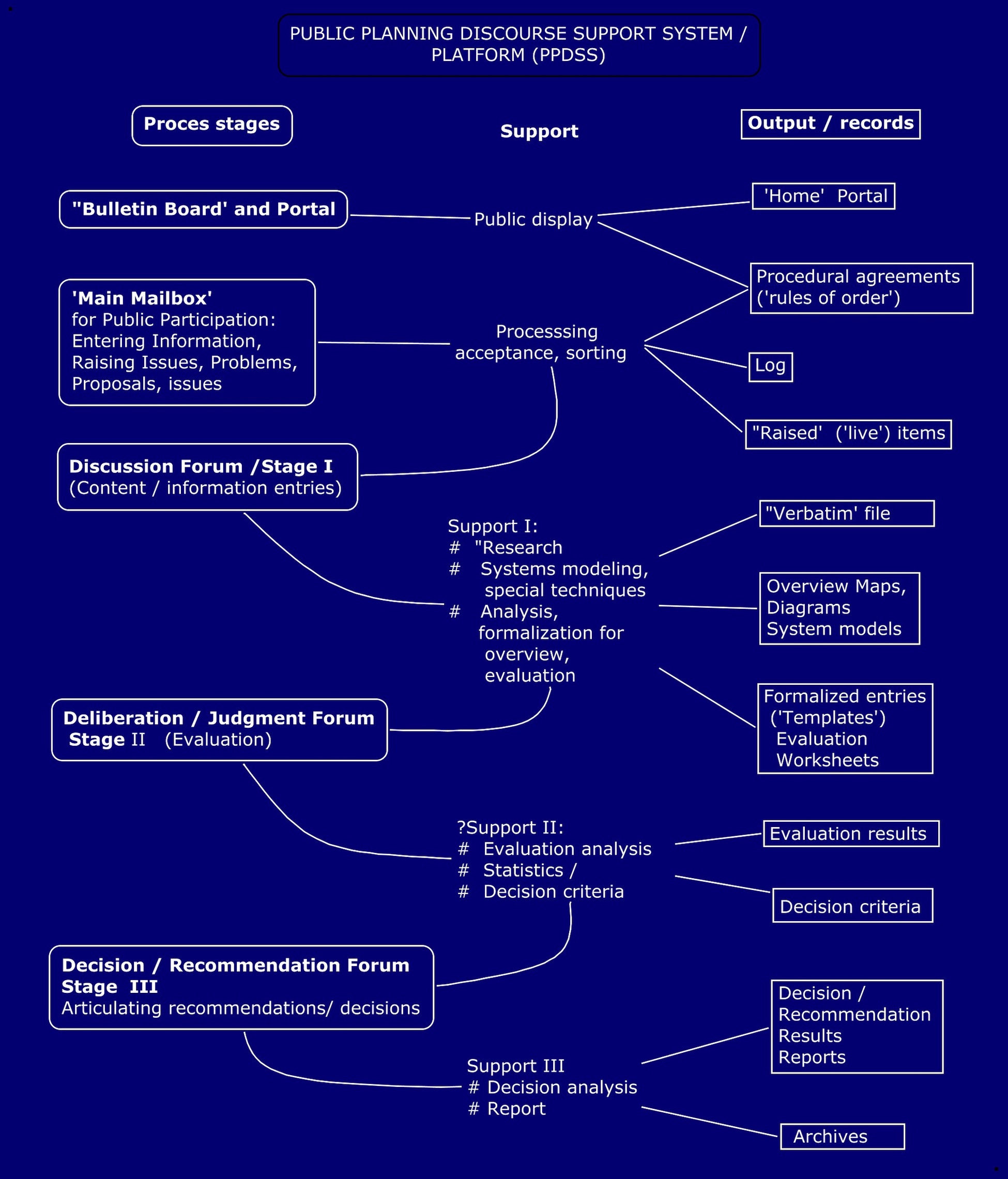
So I would like to post some of the components (chunks) one by one — posting one a day or so, just keeping the overall scheme in mind that holds them all together: the diagram shows the relationships between the topics.
At any time, participants in the discussion or interested observers who get the feeling that it — and the topics listed — are somehow ‘missing the problem’ or wasting time on a ‘wrong question’ should feel free to make that objection, but try to state the ‘real problem’ or better question for consideration. So all the topics will have this ‘wrong question?’ reminder at the end, that may lead to changes in the sequence, and will be summarized in the end, before a final question or effort (hope) to articulate some ‘conclusion’ or recommendation based on the information and questions contributed.
A first suggested list of ‘chunks’ for discussion: (Items added in response to reader suggestions (from FB discusion) shown in italic)
The need for a public planning discourse support system (1 abiove)
The need for better controls of power
The Goals of the System (2)
The platform (3)
Participation Incentives (4)
The ‘Verbatim’ record (5)
Power and the discourse platform (
* Procedural agreements
* Formalization of entries (6)
* Displays of the process
* ‘Next Step’?
* Decision Modes
* Evaluation
Formal ‘Quality’ Evaluation
Solution plausibility based on Argument Evaluation
* Decision Criteria
* Discourse contribution merit accounts
* ‘Paying for power decisions’
* Pricing power decisions
* Transfer of merit points
* Other possible uses of merit accounts
Implementation: Experiments, Games: ‘Skunkworks”
Brief discussions of these topics for discussion will be added — not necessarily in the same order, in response to reader suggestions
Wrong question? (E.g. “Is the Power issue -Discurse Platform connection appropriate?”
2 THE GOALS OF THE SYSTEM
(In response to the question by T. Markatos: “What are the goals of the system and how do they all interrelate? Until we can answer such, we can only guess at the causalities”)
The focus of the post wasreally somewhat limited: to explore the connection between the platform and the Power issue: Specifically; the notion that the evaluation provisions of the platform would offer some new opportunities for ’taming’ power. This was based on the two assumptions
a) that such a platform is needed — for a number of reasons (or goals) I have written about and will try to summarize below — and
b) that better controls of power is also urgent, as current events demonstrate but of course also must be explored.
Let me start with (a):
Humanity faces various challenges of the ‘wicked’ kind, for which collective (even global) agreements and decisions may be needed. The current planning and policy-making tools are still inadequate to deal with these challenges: Some specific aspects needing improvements are, briefly:
– Better provisions and incentives for public participation in the planning / policy-making and decision process;
– Besides the desire for participation itself, the ‘distributed’ nature of the information about how problems and proposed solutions affect different parts of society (i.e. information not yet documented) calls for better access and incentives for collaborately contributing such information in a timely fashion;
– Current media and governmental means of informing the public increasingly suffer from polarization (channles only presenting information supporting selected perspectives and interests, from repetition of claims, but lack of concise overview of the essence of available information;
– The lack of transparency of how the contributions support (or fail to support) governments’ eventual decisions, thus meeting the aim that decisions be transparently based on the merit of the available information;
– The lack of adequate measures of that merit’; that is, the pervasive inadequacy of systematic evaluation in the process, supporting understandable decision criteria that can be compared with actual decisions;
– The inappropriateness of decision modes (such as voting, even in the form of referendum-like procedures, that do not apply well to problms and crises affecting populations across traditional governance boundaries;
– The vulnerability of even the best ‘democratic’ government structures to the corrosive effects of money (corruption) and and the effects and temptations of power.
– The potential of innovative information technology appears to have contributed more to the increase of the problems than to their resolution.
These are some of the major concerns and expectations for a better planning and policy-making platform; that have guided my suggestions so far; more can certainly be added; all for discussion. For example, the paper Towards a Model for Survival” (Academia .edu) that resulted from my observations of a lengthy (2011-2015) discussion on the Systems Thinking group on LInkedIn addresses the concerns of such a platform in view of mutual sharing and ealuating the information of the many small ‘alternative’ initiatives already underway to grapple with the challenges leading then UN General Secretary Ban Ki Moon to call for ‘revolutionary thinking and action for an economic model for survival’ at the 2011 Davos meeting of the World Economic Forum. The many experienced and thoughtful participants in that Systems Thinking group did not come to an agreement on what such a model would look like.
3 PUBLIC PLANNING DISCOURSE: THE PLATFORM
There ought to be a common PLATFORM for a better organized public discussion of plans, issues and policies? Inviting all affected, interested, concerned parties to participate, to contribute questions, information and opinions in a way that transparently influences the eventual decisions about the plan.
Such a platform is needed for plans, policies, agreements involving societal (and global) ‘wicked’ problems and issues that transcend traditional governance boundaries and for which conventional decision-making practices are inappropriate or inadequate.
Ideas for such a platform have been described in e.g. ‘P D S S’ papers on Academia.edu. and other posts on Facebook and this blog Abbeboulah.com.)
The diagram shows its basic components. It must be impartial, that is, open to all parties in controversial issues, even offer meaningful incentives for participation, but have provisions for the critical assessment of contributed, and aim at developing guidelines and criteria for decision that are transparently based on such assessments.
4 INCENTIVES FOR PARTICIPATION
The platform should have provisions for acknowledging and rewarding contributions.
This is necessary not only to encourage public participation for its own sake, but also to help getting the ‘distributed information’ about wicked problems into the process for consideration — the different perspectives of how both problems and proposed solutions affect different segments of society, and also to establish the mechanism for meaningful evaluation.
Incentive rewards must be distinguished according to the kinds of contributions (questions, answrs, solution proposals, pro and con arguments etc.
The incentives will have to be in a different ‘currency’ from money, but ‘fungible’ that is, potentially becoming practically useful in some way, within the process and outside.
It is of course necessary to prevent the system from becoming overwhelmed by ‘information overload’ and redundant, useless or even disruptive content. This could be done by offering initial ‘empty’, mere ‘acknowledgement’ points but
’activating the value’ of these points only for the ‘first’ entry of essentially the same content, (which will also encourage getting information ‘fast’, and
modifying the value of the points in the later process of evaluation, according to their merit, not only upwards’ for positive, important and helpful contributions, but also ‘downward’ for false, disruptive, meaningless content.
Expressions of ‘endorsement’ of other posts or positions will be accommodated in the later ‘evaluation’ stage.
5 THE ‘VERBATIM’ RECORD
The platform will have provisions for accepting entries in various ‘media’: letters, phone calls, text messages, recordings of interviews, emails, citation from other documented sources. They must be recorded in the form they were submitted (even though this may not be in a format suitable for systematic evaluation yet, and appear irritating to some). They must be accessible for reference («what did the author really say?») Each entry must be tagged with the author’s ID — a question to be discussed is whether and to what extent authors’ actual names should be publicly visible.
For evaluation of contribution merit, this may not be needed or appropriate (a comment should be taken on the merit of its content?) But it will be necessary if assignment and valuation of merit points to their authors is to be provided. The collection of entries should be structured according to topics and issues, in chronological order. Authors will therefore have to indicate the issue an entry is aimed at.
A common habit is the posting of links to other sites or documents; should there be a rule to state explicitly what claims are to be taken as being introduced or supported by a link or reference? The question of how general ‘arguments from authority’ be treated will become critical in any later more systematic evaluation; if that task requires consideration of specific parts or premises — when and how should that be inntroduced into the process?
6 FORMALIZATION OF ENTRIES
Meaningful overview display of the state of discussion as well as systematic evaluation will require organized presentation of entries in some commonly understandable, coherent format (For example, ‘pro’ or ‘con’ arguments out proposed plans might be represented in a format or ‘template’ such as
“Plan A ought to be adopted
because
A will result in outcome B’
and
B ought to be pursued (desirable)”
Such templates will have to be developed and agreed upon for the different types of planning discourse contributions: Questions, answers, problems, solution proposals, evaluation criteria and judgments, etc. Participants may be encouraged to submit or ’translate’ their verbatim comments into an appropriate template, or the support system will have to do this, perhaps call for the author’s consent («Is this what you mean?») Many verbatim comments will be ‘enthymemes’ — e.g. arguments in which some premises are left unstated as ‘taken for granted’ — but for overview and systematic evaluation, they must be stated explicitly.
The templates may look unsatisfactory and too crude to trained logicians — forms like the ‘planning argument’ proposed above have not been acknowledged and studied by formal logic since it is not a ‘deductively valid’ form. Arguably, for lay public participation, the templates should be as close to conversational language as possible, at the expense of disciplinary rigor. (Of course, this is an issue requiring discussion.
[ 7 ] DISPLAYING THE STATE OF DISCOURSE
A planning discourse aiming at providing adequate information for making collective decisions will need a system of displaying the proposed plans or questions to be discussed, as well as the state and content of the discourse. This will include a public ‘Bulletin board’ that shows what plans, issues are being proposed (‘candidates’) and those accepted for discussion, and their state of process until decision and closure.
The important principle is that all different positions about controversial issues must be properly represented, to avoid the polarization of political discourse currently caused by news media channels only presenting material supporting one partisan perspective.
For initial purposes such as to determine whether a proposed issue candidate should be accepted for full organized discourse, the common current format of social media may be sufficient. That format will soon become too unwieldy for participants to gain and keep an adequate overview of the state of discussion. Topic and issue ‘maps’ (diagrams showing the concepts and topcis that have been raised, and their relationships )— may be needed, to be updated as the discourse evolves. The relationship connections in issue maps are simply those of ‘issue or question x has been raised in response to question y’. Diagrams of systems models’ and system behavior over time would focus on relationships such as cause-effect or ‘flows’ between ’stocks’. Ideally, the support system would provide such understanding and orientation aids, drawing as needed on the service of consultants or ‘special technique’ processes for gathering specific information, predicting the expected benefits and cost performance of proposals, etc. the participants may call for.
Comments?
8 POWER AND THE DISCOURSE PLATFORM
The general question whether new tools for dealing with the problems of power should not need much explanation. In almost all current societies and government forms as well as in view of the issue of a ‘world government’, the presence of power-related corruption in various forms, and the abuses of government leaders who have gained even just close to ‘total’ authoritarian power are well known and much deplored. And the provisions of ‘democratic’ constitutions that have arguably proven successful within the governance systems are showing increasingly disturbing vulnerability to the intrusions and influence of money and partisan information — from wealthy oligarchs, religious institutions, and huge national and multi-national corporations that control public information media and election financing.
However, the problem of power in general is too vast for this discussion, and a more general discussion is urgent in its own right. The key thesis of this limited discussion can be stated as follows: “Some problems of power (and abuse of power) can be at least partially remedies or mitigated by certain provisions in a better organized public planning and policy-making discourse support platform.” It is necessary to stress the ‘partial’ qualification; though it can be argued that it requires at least some understanding of the overall problem to assess whether and how discourse platform provisions can make a difference.
Platform provisions and power
How might a better public planning discourse make a difference in taming power? There are several ways in which specific interrelated provisions could help:
* Empowerment of the public, through provisions that incentivize contributions to the discourse
* Evaluation features that help constructing measures of merit of proposed plans, based on discourse contributions; and thus guide decisions;
* The establishment of contributors’ ‘discourse merit accounts‘ from the evaluated contributions (a by-product of the plan evaluation process);
* The use of these accounts by public officials to “Pay for decisions” and their implementation — merit points they have ‘earned’ as well as points citizen supporters may have contributed to the officials’ accounts — for decisions too important to be paid for by a single person’s account. This different ‘currency’ may replace or at least lessen the role of money in public decisions. Citizens can also withdraw their merit point contributions if they lose confidence in the performance of officials;
* In this way, citizens become empowered but also ‘co-accountable‘ for the decisions they authorize officials to make, and the officials will eventually ‘use up’ the points that constitute their power, instead of amassing evermore power and wealth gained form illicit power abuse.
These ideas will of course have to be discussed in more detail, as well as, hopefully, any better alternative suggestions they provoke?
Wrong question:?
a) ]What makes this issue a dilemma is the fact that some events, crises, problems require ‘fast’ decisions that can’t wait for lengthy public discourse; that is, these decisions must be made by people given the responsibility and the power to decide. The power must be adequate to confront the scope of the problems, and to ensure that its provisions are then followed / adhered to. This usually involves some form of ‘enforcement’: logically by a power greater (more forceful) than any potential violator. Does this mean that the power must also be greater that any entity trying to ‘tame’ or ‘control’ that power?
b) The real problem with power (in the public domain) is corruption; so any efforts to deal with power must start with the role of potential sorption in the governance system; which may ultimately be seen as the problem of the role of money in the governance and policy-making process.
—–
9 PAYING FOR POWER DECISIONS
The incentive and evaluation provisions of the proposed platform offer an innovative opportunity for taming power: having public officials ‘pay’ for decisions with the ‘merit points’ they have earned with their contributions to the discourse
Rationale
We think of the desire of people to strive for more freedom to make decisions for themselves and their community as a kind of human right: in line with the right to life, food, shelter, the pursuit of happiness: “empowerment”. And we are accustomed to the fact that we also have to work for, and pay for the realization of these pursuits or needs. But when the empowerment extends to decisions on behalf of or even over the desire of other people, (perhaps as one of those power decisions), the custom is curiously reversed: people with power expect to get paid for the satisfaction of that desire. And part of the temptation and addiction of such power is the forcefully pursued expectation to continually increase such payment. Which leads to the abuse of power.
There are of course more features and systemic loops involved, that deserve to be studied more thoroughly, but for the current purpose of this study, we can go straight to the reversed question of “What if the power to making collective decisions that affect others, or the entire community, is a right that also had to be paid for?” Of course, there would be objections to extenuating the already problematic role of money to this, But the proposed PPDSS platform provisions of incentives that become merit reward points that people accumulate in ‘merit point accounts’ constitute a different ‘currency’ — a kind of ‘reputation’ account, now given some actual measurement units — could offer a practical way of realizing this, and thus become a means for curbing the tendency for evermore powerful decisions: If a public official had to ‘pay’ for the power of making decisions, that power would diminish and disappear when those reputation merit points run out.
Implementation.
This idea could be realized with some technology that arguably is already available.
One form might be upfront payments for the ‘license’ to make certain domain-specific decisions, and a mechanism to withdraw points from the officials’ merit point account, as a power decision gets recorded for iacceptance and mplementation of a plan or activity. Or there could be devices requiring such payments as a decision is attempted: the ‘button’ for activation can be activated only with the ‘merit point card’.
This provision would be especially useful to be applied to decisions that must be made ‘fast’, for which there is no time for lengthy public discussion.
A further opportunity of this feature might be the ability of citizens to ‘support’ officials (or plans to be decided upon), that individual accounts of office holders would not cover, by transferring some of citizens merit points to the official. Citizen might be allotted a certain basic merit point amount — a version of voting rights — that can be increased with discourse merit points (like the widely discussed basic guaranteed basic income), to actually become empowered and also co-accountable for collective decisions. Citizens would also have to be able to recall such support payments if the official doe not make proper intended use of them — but only before they are used…
Of course, this idea needs development, discussion, experimentation — perhaps as a ‘game’ version’ or more elaborate opinion surveys ‘skunkworks’ projects — ‘parallel to existing practice, before actual implementation.
Comments?
Wrong question?
——
10 EVALUATION OF DISCOURSE CONTRIBUTIONS 4/5/22
The general topic of evaluation and the literature about it is vast. So one might suppose that everything significant and useful has been said or written about it. Still, it is fair to state that practical application in planning and policy-making lags far behind the theoretical and methodological insights that have been produced over time. Part of the reason for this discrepancy may be practical and the lack of adequate technological tools. And for the assessment of the role of evaluation in a better orchestrated planning discourse support system using available new technology, some new issues emerge that require consideration and discussion.
A first necessary step may be the clarification of different evaluation tasks that occur throughout the planning process: it is not just a final formal evaluation of a proposed plan to guide the decision. A distinction must be made between
* the ‘quality’ assessment of a proposed plan as compared to an existing (‘do nothing’) option, and
* the assessment of the merit of discourse contributions towards that decision: even a ‘con’ argument against a proposal (that may be good enough for eventual acceptance) has ‘merit’ that should be acknowledged and rewarded. So the ‘merit’ assessment is a related but distinctly different task from the determination of the ‘quality’ evaluation of the proposed plan. The relationship, of course, maybe the cause of potential confusion and misunderstanding, as well as the continued controversy about ‘objective’ and ‘subjective’ properties and judgments in the assessment of both plan quality and contribution merit.
Evaluation judgments of different kinds occur throughout the planning discourse. A quick overview shows this:
– Problems, Issues, Questions, Answers, Plan Proposals (‘Solutions’) are raised and must be assessed for acceptance on an agenda of public discussion;
– For each accepted agenda items, new entries must be assessed for pertinence and salience (importance?) to the topic (and sub-categories, if any), for acceptance and assignment sorting; ‘Netiquette’ considerations — e.g. language and ad-hominem comments etc. may play a role here as well.
– Assuming some forms of participation incentives and reward are going to be part of the process, each accepted entry may be given some ‘basic’ participation reward. If ‘only the first’ entry of the same content is to be entered into any organized assessment scheme (and to avoid ‘information overflow’ with essentially the same content), a judgment of identity or similarity of items expressed in slightly different wording may be needed. Entries with different degrees of detail may have to be even given different ‘basic’ points that comments addressing only one feature or detail claim. (These ‘basic participation points (or vehicles for merit assessments) will be modified according to evaluation results by the participant community later on.)
– Depending on agreements regarding the procedures to be followed in each specific project, participants may express first ‘overall offhand’ judgments about
* the plausibility, coherence, validity or other merit of an entry (according to the entry type); and
* the ‘quality’ (goodness, desirability, or lack of such) of a plan solution or detail.
The judgments must be expressed on some agreed-upon scale- respectively, of plausibility (e.g. -1 ≤ pl ≤ +1) ore
quality q, (e.g. -3 ≤ q ≤ +3).
– For more systematic deliberation and evaluation, It may be necessary to ‘formalize’ entries — that is, express the content of an entry, in some concise (agreed-upon) formal ‘template’; this may involve adding of e.g. explicit assumptions of premises not stated in a ‘verbatim’ comment but ‘taken for granted’. For example, argument ‘pro or con’ a proposed plan PP may be presented in the following ‘template’ form:
(‘Conclusion’:) PP ought to be accepted, because
(Factual – Instrumental Premise 1) “PP will result in effect/outcome R, and
(Ought- Premise 2) Outcome R ought to be pursued.”
Or the more elaborate template
(‘Conclusion’:) PP ought to be accepted, because
(Factual – Instrumental Premise 1) “Given conditions C1, PP will result in effect/outcome R, and
(Ought-Premise 2) Given conditions C2, Outcome R ought to be pursued, and
(Fact-Premise 3) Conditions C1 are / will be present, and
(Fact-Premise 4) Conditions C2 are / will be present.”
– Participants may at this point, upon reviewing displays of all such formalized items, revise their earlier Overall Offhand Plausibility of argument merit or Quality of solution assignments. The initial merit points will be modified with the results of the group statistics.
– If more detailed evaluation is agreed upon, the steps of Argument evaluation will require assignment of plausibility to each argument premise, and ‘weight of relative importance’ w to the ought-premises (on an agreed-upon scale of e.g. 0 ≤ w ≤ +1 such that ∑w = +1) to derive Argument weights and, adding all of those to a ‘Deliberated Proposal Plausibility score PPPL. Statistical measures of these Judgments by the groups will be used to revise the merit assignment to individual merit points.
For Quality evaluation, steps for e.g. the formal quality evaluation procedure [1] can be followed: From the discussion, ‘Quality’ aspects may be derived, to construct an ‘aspect tree’; each aspect given a weight w of relative importance, and a quality estimate (on the agreed-upon scales); each aspect may be further deliberated, with each new sub-aspect branch being evaluated in the same way. It can be helpful if participants can express how their quality judgments relate to some objective performance measure or ‘criterion’ in a ‘criterion function’. For each participant, each quality judgment is then revised as a function of the respective sub-aspect quality scores and their weights. Again, the Individual Overall Deliberated Quality judgments can be revised to that Individual’s earlier judgments, and these be modified according to some agreed-upon statistic of all the group’s Individual judgments.
Delphi Method or similar additions to these procedures can be added to further deliberate the supporting evidence of judgments, as needed.
Thee procedures are recommended selections from any larger set of ‘special procedures’ such a group may draw upon.
– The group’s judgments may be used to derive statistical measures (not ‘group judgments”: ‘groups’ do not ‘have’ unified judgments, especially if there are significant differences in the individual participants’ judgments) to for ‘decision guides. The group will have to discuss and decide on how these will determine their final decision or decision recommendation.
– If participant entries are also to be modified according to whether and do what degree they have influenced the group’s decision, a measure of such influence must be developed and then applied to the respective contribution.
– If the merit point accounts are to be used for ‘Pay for Power” decisions, it will be necessary to devise a method for setting the price for such decisions; this remains to be explored. Candidate considerations are, In a first no-particular order list::
* The number of people affected by the problem a project is addressing, and of the proposed solution alternatives;
* The total cost of a project — including the risk of expected failure over time;
* The difference between the decision guide results and the decision taken.
Wrong question?
– The usual evaluation techniques do not easily include such aspects as ‘image’ (Who are we, as a result of a decision like this, as compared to the kind of person/people we wold like, or pretend, or feel obligated to be? This is, at best, brought up in the discourse, if at all, by comments such as ‘That’s not who we are’; aspect difficult to explain and to quantify. As an example, the categorizations of movements in art or architecture are mostly labels that the actual artists or decision-makers and even critics are not consciously able to clearly articulate until much later.
– The number of judgment types listed and the steps needed to construct meaningful contribution merit point accounts much less pricing provisions decision-maker would be asked to ‘pay’ for making decision may appear too complex to be understandable and acceptable to the ‘public’ called upon to participate in. So participation in planning discourse may end up becoming even more of activities limited to a kind of experts or ‘elite’ than is currently the case. Will a consideration of the consequences of continuing current practices overcome such objections?
– The need for improved global planning discourse and evaluation approaches is urgent; there is no time for the gradual education, familiarization and implementation required: More streamlined, simple, perspective-neutral and understandable tools are needed.
Diagram: the relationships between discourse provisions and power
Thorbjørn Mann Updated (adding section 8) 3/27/2022
I submit, for discussion, that better controls of power are desperately needed, as are public (global) decision-making tools that better — that is, more transparently — link the merit of discourse contributions with the decisions, and that the development of a better discourse platform with some provisions for evaluation of contributions can offer both:
1 THE URGENT NEED FOR PUBLIC (GLOBAL?) PLANNING DISCOURSE PLATFORM , DECISIONS BASED ON DISCOURSE CONTRIBUTION MERIT, AND CONTROL OF POWER
Tall order: I agree, and I expect that many will find it impossible, if only because it looks too complex. Plausible — but is it reasonable to expect that complex problems can be ‘fixed’ with simple tricks? Some potential provisions I have found while working on improvements to planning decision-making suggest to me that better tools for both the discourse decision-making and the power control issue are possible, and that they should be discussed, as well as that the search for other, better answers should be pursued more intensively than what I currently see.
To support my perhaps naively optimistic hypothesis but also to invite critical comments and better ideas, I suggest to break up the discussion into ‘chunks’ that can be discussed in more depth; the effort to present the whole ‘system’ in its overall complexity has always led to larger, even book-size articles whose very size discourage discussion if they even get read.
So I would like to post some of the components (chunks) one by one — posting one a day or so, just keeping the overall scheme in mind that holds them all together: the diagram shows the relationships between the topics.
At any time, participants in the discussion or interested observers who get the feeling that it — and the topics listed — are somehow ‘missing the problem’ or wasting time on a ‘wrong question’ should feel free to make that objection, but try to state the ‘real problem’ or better question for consideration. So all the topics will have this ‘wrong question?’ reminder at the end, that may lead to changes in the sequence, and will be summarized in the end, before a final question or effort (hope) to articulate some ‘conclusion’ or recommendation based on the information and questions contributed.
A first suggested list of ‘chunks’ for discussion: (Items added in rspnse to reader suggestions (from FB discusion) shown in italic)
The need for a public planning discourse support system (1 abiove)
The need for better controls of power
The Goals of the System (2)
The platform (3)
Participation Incentives (4)
The ‘Verbatim’ record (5)
* Procedural agreements
* Formalization of entries (6)
* Displays of the process (7)
Power and the discourse playtform (8)
* ‘Next Step’?
* Decision Modes
* Evaluation
Formal ‘Quality’ Evaluation
Solution plausibility based on Argument Evaluation
* Decision Criteria
* Discourse contribution merit accounts
* ‘Paying for power decisions’
* Pricing power decisions
* Transfer of merit points
* Other possible uses of merit accounts
Implementation: Experiments, Games: ‘Skunkworks”
Brief discussions of these topics for discussion will be added — not necessarily in the same order, in response to reader suggestions
Wrong question? (E.g. “Is the Power issue -Discourse Platform connection appropriate?”
—-
2 THE GOALS OF THE SYSTEM
(In response to the question by T. Markatos: “What are the goals of the system and how do they all interrelate? Until we can answer such, we can only guess at the causalities”)
The focus of the post wasreally somewhat limited: to explore the connection between the platform and the Power issue: Specifically; the notion that the evaluation provisions of the platform would offer some new opportunities for ’taming’ power. This was based on the two assumptions
a) that such a platform is needed — for a number of reasons (or goals) I have written about and will try to summarize below — and
b) that better controls of power is also urgent, as current events demonstrate but of course also must be explored.
Let me start with (a):
Humanity faces various challenges of the ‘wicked’ kind, for which collective (even global) agreements and decisions may be needed. The current planning and policy-making tools are still inadequate to deal with these challenges: Some specific aspects needing improvements are, briefly:
– Better provisions and incentives for public participation in the planning / policy-making and decision process;
– Besides the desire for participation itself, the ‘distributed’ nature of the information about how problems and proposed solutions affect different parts of society (i.e. information not yet documented) calls for better access and incentives for collaborately contributing such information in a timely fashion;
– Current media and governmental means of informing the public increasingly suffer from polarization (channles only presenting information supporting selected perspectives and interests, from repetition of claims, but lack of concise overview of the essence of available information;
– The lack of transparency of how the contributions support (or fail to support) governments’ eventual decisions, thus meeting the aim that decisions be transparently based on the merit of the available information;
– The lack of adequate measures of that merit’; that is, the pervasive inadequacy of systematic evaluation in the process, supporting understandable decision criteria that can be compared with actual decisions;
– The inappropriateness of decision modes (such as voting, even in the form of referendum-like procedures, that do not apply well to problms and crises affecting populations across traditional governance boundaries;
– The vulnerability of even the best ‘democratic’ government structures to the corrosive effects of money (corruption) and and the effects and temptations of power.
– The potential of innovative information technology appears to have contributed more to the increase of the problems than to their resolution.
These are some of the major concerns and expectations for a better planning and policy-making platform; that have guided my suggestions so far; more can certainly be added; all for discussion. For example, the paper Towards a Model for Survival” (Academia .edu) that resulted from my observations of a lengthy (2011-2015) discussion on the Systems Thinking group on LInkedIn addresses the concerns of such a platform in view of mutual sharing and ealuating the information of the many small ‘alternative’ initiatives already underway to grapple with the challenges leading then UN General Secretary Ban Ki Moon to call for ‘revolutionary thinking and action for an economic model for survival’ at the 2011 Davos meeting of the World Economic Forum. The many experienced and thoughtful participants in that Systems Thinking group did not come to an agreement on what such a model would look like.
3 PUBLIC PLANNING DISCOURSE: THE PLATFORM
There ought to be a common PLATFORM for a better organized public discussion of plans, issues and policies? Inviting all affected, interested, concerned parties to participate, to contribute questions, information and opinions in a way that transparently influences the eventual decisions about the plan.
Such a platform is needed for plans, policies, agreements involving societal (and global) ‘wicked’ problems and issues that transcend traditional governance boundaries and for which conventional decision-making practices are inappropriate or inadequate.
Ideas for such a platform have been described in e.g. ‘P D S S’ papers on Academia.edu. and other posts on Facebook and this blog Abbeboulah.com.)
The diagram shows its basic components. It must be impartial, that is, open to all parties in controversial issues, even offer meaningful incentives for participation, but have provisions for the critical assessment of contributed, and aim at developing guidelines and criteria for decision that are transparently based on such assessments.
4 INCENTIVES FOR PARTICIPATION
The platform should have provisions for acknowledging and rewarding contributions.
This is necessary not only to encourage public participation for its own sake, but also to help getting the ‘distributed information’ about wicked problems into the process for consideration — the different perspectives of how both problems and proposed solutions affect different segments of society, and also to establish the mechanism for meaningful evaluation.
Incentive rewards must be distinguished according to the kinds of contributions (questions, answrs, solution proposals, pro and con arguments etc.
The incentives will have to be in a different ‘currency’ from money, but ‘fungible’ that is, potentially becoming practically useful in some way, within the process and outside.
It is of course necessary to prevent the system from becoming overwhelmed by ‘information overload’ and redundant, useless or even disruptive content. This could be done by offering initial ‘empty’, mere ‘acknowledgement’ points but
1 activating the value’ of these points only for the ‘first’ entry of essentially the same content,(which will also encourage getting information ‘fast’, and
modifying the value of the points in the later process of evaluation, according to their merit, not only upwards’ for positive, important and helpful contributions, but also ‘downward’ for false, disruptive, meaningless content.
Expressions of ‘endorsement’ of other posts or positions will be accommodated in the later ‘evaluation’ stage.
5 THE ‘VERBATIM’ RECORD
The platform will have provisions for accepting entries in various ‘media’: letters, phone calls, text messages, recordings of interviews, emails, citation from other documented sources. They must be recorded in the form they were submitted (even though this may not be in a format suitable for systematic evaluation yet, and appear irritating to some). They must be accessible for reference («what did the author really say?») Each entry must be tagged with the author’s ID — a question to be discussed is whether and to what extent authors’ actual names should be publicly visible.
For evaluation of contribution merit, this may not be needed or appropriate (a comment should be taken on the merit of its content?) But it will be necessary if assignment and valuation of merit points to their authors is to be provided. The collection of entries should be structured according to topics and issues, in chronological order. Authors will therefore have to indicate the issue an entry is aimed at.
A common habit is the posting of links to other sites or documents; should there be a rule to state explicitly what claims are to be taken as being introduced or supported by a link or reference? The question of how general ‘arguments from authority’ be treated will become critical in any later more systematic evaluation; if that task requires consideration of specific parts or premises — when and how should that be inntroduced into the process?
Comments?
6 FORMALIZATION OF ENTRIES
Meaningful overview display of the state of discussion as well as systematic evaluation will require organized presentation of entries in some commonly understandable, coherent format (For example, ‘pro’ or ‘con’ arguments out proposed plans might be represented in a format or ‘template’ such as
“Plan A ought to be adopted
because
Plan A will result in outcome B
and
Outcome B ought to be pursued (desirable)”
Such templates will have to be developed and agreed upon for the different types of planning discourse contributions: Questions, answers, problems, solution proposals, evaluation criteria and judgments, etc. Participants may be encouraged to submit or ’translate’ their verbatim comments into an appropriate template, or the support system will have to do this, perhaps call for the author’s consent («Is this what you mean?») Many verbatim comments will be ‘enthymemes’ — e.g. arguments in which some premises are left unstated as ‘taken for granted’ — but for overview and systematic evaluation, they must be stated explicitly.
The templates may look unsatisfactory and too crude to trained logicians — forms like the ‘planning argument’ proposed above have not been acknowledged and studied by formal logic since it is not a ‘deductively valid’ form. Arguably, for lay public participation, the templates should be as close to conversational language as possible, at the expense of disciplinary rigor. (Of course, this is an issue requiring discussion.
Comments?
[ 7 ] DISPLAYING THE STATE OF DISCOURSE
A planning discourse aiming at providing adequate information for making collective decisions will need a system of displaying the proposed plans or questions to be discussed, as well as the state and content of the discourse. This will include a public ‘Bulletin board’ that shows what plans, issues are being proposed (‘candidates’) and those accepted for discussion, and their state of process until decision and closure.
The important principle is that all different positions about controversial issues must be properly represented, to avoid the polarization of political discourse currently caused by news media channels only presenting material supporting one partisan perspective.
For initial purposes such as to determine whether a proposed issue candidate should be accepted for full organized discourse, the common current format of social media may be sufficient. That format will soon become too unwieldy for participants to gain and keep an adequate overview of the state of discussion. Topic and issue ‘maps’ (diagrams showing the concepts and topcis that have been raised, and their relationships )— may be needed, to be updated as the discourse evolves. The relationship connections in issue maps are simply those of ‘issue or question x has been raised in response to question y’. Diagrams of systems models’ and system behavior over time would focus on relationships such as cause-effect or ‘flows’ between ’stocks’. Ideally, the support system would provide such understanding and orientation aids, drawing as needed on the service of consultants or ‘special technique’ processes for gathering specific information, predicting the expected benefits and cost performance of proposals, etc. the participants may call for.
Comments?
[ 8 ] POWER AND THE DISCOURSE PLATFORM
The general question whether new tools for dealing with the problems of power should not need much explanation. In almost all current societies and government forms as well as in view of the issue of a ‘world government’, the presence of power-related corruption in various forms, and the abuses of government leaders who have gained even just close to ‘total’ authoritarian power are well known and much deplored. And the provisions of ‘democratic’ constitutions that have arguably proven successful within the governance systems are showing increasingly disturbing vulnerability to the intrusions and influence of money and partisan information — from wealthy oligarchs, religious institutions, and huge national and multi-national corporations that control public information media and election financing.
However, the problem of power in general is too vast for this discussion, and a more general discussion is urgent in its own right. The key thesis of this limited discussion can be stated as follows: “Some problems of power (and abuse of power) can be at least partially remedies or mitigated by certain provisions in a better organized public planning and policy-making discourse support platform.” It is necessary to stress the ‘partial’ qualification; though it can be argued that it requires at least some understanding of the overall problem to assess whether and how discourse platform provisions can make a difference.
How might a better public planning discourse make a difference in taming power? There are several ways in which specific interrelated provisions could help:
* Empowerment of the public, through provisions that incentivize contributions to the discourse
* Evaluation features that help constructing measures of merit of proposed plans, based on discourse contributions; and thus guide decisions;
* The establishment of contributors’ ‘discourse merit accounts‘ from the evaluated contributions (a by-product of the plan evaluation process);
* The use of these accounts by public officials to “Pay for decisions” and their implementation — merit points they have ‘earned’ as well as points citizen supporters may have contributed to the officials’ accounts — for decisions too important to be paid for by a single person’s account. This different ‘currency’ may replace or at least lessen the role of money in public decisions. Citizens can also withdraw their merit point contributions if they lose confidence in the performance of officials;
* In this way, citizens become empowered but also ‘co-accountable‘ for the decisions they authorize officials to make, and the officials will eventually ‘use up’ the points that constitute their power, instead of amassing evermore power and wealth gained form illicit power abuse.
These ideas will of course have to be discussed in more detail, as well as, hopefully, any better alternative suggestions they provoke?
Wrong question?
a) ]What makes this issue a dilemma is the fact that some events, crises, problems require ‘fast’ decisions that can’t wait for lengthy public discourse; that is, these decisions must be made by people given the responsibility and the power to decide. The power must be adequate to confront the scope of the problems, and to ensure that its provisions are then followed / adhered to. This usually involves some form of ‘enforcement’: logically by a power greater (more forceful) than any potential violator. Does this mean that the power must also be greater that any entity trying to ‘tame’ or ‘control’ that power?
b) The real problem with power (in the public domain) is corruption; so any efforts to deal with power must start with the role of potential sorption in the governance system; which may ultimately be seen as the problem of the role of money in the governance and policy-making process.
Just protesting and even ‘better understanding’ is no longer enough.
I fully support the many calls for protest and condemnations against the Putin invasion of Ukraine. And to contribute donations to help refugees and victims of this unprovoked war: providing band-aids for the wounds our inability to prevent the war has caused?
What I am missing is more of an effort to discuss, understand, and find remedies for the underlying forces that led to this — and similar situtions. Because it seems obvious to me that the provisions humanity has tried to put in place so far, are critically ineffective.
The problem is the use and misuse of power in societal governance and conflict. More specifically: the apparently unquestioned assumption that conflicts and violations of laws, treaties and agreements can only be prevented, and must be punished, by the threat and application of force or forceful ‘sanctions’.
We have long known, from examples of abuses of power form antiquity to current events, that power is addictive, that it seems to destroy the mental sanity of the holders of power — the more so, the greater the power they hold —; because mistakes, arbitraniness and evil intent in its application will generate both fear and resistance, opposition. Fear, both in the oppressed and the powerful. because if they adhere to the above assumption that power is acquired, and sustained by force, they must be afraid that force will be used against them as well. This creates a vicious circle of escalation of power use and abuse, and opposition resistance.
For the relationships among nations, this is the ultimate dilemma: the ‘World government dilemma’: If violations of treaties and human rights by force (and similar means) can only be ‘prevented’ by the threat of more powerful force, the question necessarily arises: what will prevent that superior entity itself from falling victim to the temptation and vicious cycles of power? And equally likely: Given the kinds of weapons for conflict resolution by force that now is available to contenders for global governance, the outcome of such a conflict has best been described by the alleged Einstein comment that we don’t know what kinds of weapons will be used in WW3 — but we know that any WW4 will be fought with stones and sticks: ‘civilization’ as we know it will have destroyed itself.
What is the lesson? Is this a dilemma that cannot be resolved? Then what? Can we afford to give up hope that better solutions can be found? Can we put our faith in future history books —if they won’t be burned — that will tell of our heroism in just resisting, fighting power in an unwinnable battle, if we don’t submit to the ultimate tyrranny or mutual destruction? If there is the slightest possibility of finding better ways around the dilemma — is it not our responsibility to find and try to implement them, while there still is time?
I believe there are possible answers. I believe one partial answer lies in the development of ‘sanctions’ that don’t rely on ‘enforcement’ by a greater power but that will be based on a principle of (agreed-upon) preventive measures automatically triggered by the very attempt of violation. There are already small scale examples using this approach; new technology and AI may be helpful in this effort. I cannot believe that if more effort and resources would be devoted to this problem, humanity could not find other, better answers to this dilemma. I believe that such efforts should be pursued with the highest priority, at all levels from local to global governance.
I also don’t believe that implementation of such answers, if we can find them, should be attempted via the old ‘forceful’ revolution approach, ‘regime change’, violent overthrow and bloodshed. That would just be reverting to the old problem and vicious cycles, attempting to solve the problem with its own causes. This, too, needs a better approach, such as the old ’skunkworks’ of US research and development agencies in the cold war: devoting part of ‘official contract’ resources to ‘free’ research on issues on the principle that maybe the official project is asking the ‘wrong question’ and trying to ‘solve the wrong problem’? And it needs a global platform for the impartial discussion and evaluation of any proposed answers, as heretic als they may seem. (I have explored these issues in some papers e.g. on Academia. edu.)
I am surprised and disappointed that even the ’systems thinking’ community — as far as I can see, — is not even discussing this issue much less devoting any effort, official or ‘skunkworks’-like — to this dilemma. Just focusing on a ‘better understanding ‘ of the problems, much as we do need that, is no longer enough.
Some comments on the 2019 article on A Dialectical View on Conduction: Reasons, Warrants, and Normal Suasory Inclinations by Shiyang Yu and Frank Zenker in Informal Logic, Vol. 39, No. 1 (2019), pp. 32–69.
The following comments were triggered by the article but may not be pertinent to the stated aim of the article’s aim and “Focal question: Should one treat conduction as argument-as-product?” as opposed to a dialectical view on natural language argumentation. But since the arguments I have studied in the design, planning, and policy-making discourse have at times been labeled a type of ‘conductive’ arguments, and I am interested in the ways such arguments lead to reasoned decisions, some questions arise for the implications of its views on a more systematic and transparent evaluation process within that discourse. This is, in my opinion, an urgent concern for humanity’s treatment of problems and crises that transcend traditional decision-making boundaries and practices. So I welcome any effort to devote more attention to these kinds of arguments, and hoped to find useful insights in this article.
Seen from this perspective, I am not particularly concerned about the labels give to these arguments, or whether the understanding of ‘conductive’ arguments should be narrowed (as the article seems to imply) to arguments that contain both ‘pro’ as well as ‘con’ premises or considerations: It had been my understanding that the key criterion was the presence of deontic premises to support the equally deontic ‘conclusion’. If I am mistaken in this, my comments and questions may not apply to the discussion in the article.
In my efforts to develop better evaluation approaches for arguments to ‘ought’ issues – which arguably humanity argues about as much if not more than the ‘factual’ arguments analyzed by the traditional logic sources I was aware of [1]– I found the treatment by these sources of such arguments to be of little help. In their aims for establishing compelling ‘validity’ if not ‘actually ‘truth’, some disciplines – e.g. ‘deontic logic’ seemed to actually sidestep the problem, basing the analysis on concepts like ‘permitted’, ‘mandatory’ (as e.g. by law) or ‘forbidden’, thereby turning the argument inference rule into patterns closer to the deductively valid rules such as the modus ponens, — but neglecting the subsequent issue of all such premises whether they ought to be permitted, mandatory or forbidden. Does the article make substantial progress towards a better treatment of these concerns?
Or is it possible that the effort to stay within the traditional ‘proper’ discipline approach caused the analysis to neglect to pursue key features of planning arguments that they just mention almost as side comments:
– That the presence of the deontic claims ‘ought’ or ‘should’ (as in the sample argument discussed) and its argument pattern makes the argument inconclusive by the standards of formal logic (the fancy term used is ‘defeasible’);
– That the ‘dialectical’ discourse may aim at reaching ‘normal suasive’ attitudes but that these attitudes cannot be taken for granted, in fact, the ‘arguments’ express disagreements which may be fundamental and based on irreconcilable principles;
— That planning decisions rest on often large sets of both pros and cons, not on single arguments, that arguments intended by discourse participants as ‘pro’ reasons for adopting the plan proposal, may turn into equally plausible ‘con’ arguments by other parties, if they disagree (negate) one or more of the proposed premises;
– That participants may, in the same sentence, offer both a ‘pro’ as well as a ‘con’ reason for the ‘conclusion’ (as in the ‘monster argument’ discussed [2])
My approach to these issues was the following:
* Acknowledging that planning decisions should be based on the due consideration of the many ‘pros and cons’ people affected in any way by the problems a plan aims to remedy, as well as the plan alternatives (there is always the alternative of ‘doing nothing’) the discourse should be set up to encourage and even ‘reward’ as wide participation as possible, calling for both ‘pro’ and ‘con’ arguments.
* Accepting the fact that may comments from the public will be ‘messy’, incomplete (enthymemes), even containing the disturbing ‘counter-considerations’ in one sentence that makes horrified argumentation scientists scream ’monster argument!’, organizing a more systematic, transparent evaluation process will require some formatting many comments into common argument ‘templates’ that clearly shows argument structure and missing (implied) premises. (However, original contributions must be kept for reference in a ‘verbatim’ file.)
* That re-formatting should be as close to conversational language as possible, so that authors can recognize their own intended concerns and agree to the format.
* I chose to turn the argument patterns around to state the ‘conclusion’—the plan proposal – first, with the approval or rejection claim first, linked to the following support premises with the link ‘because’ (or ‘since’ or a similar word): resulting in the pattern:
“Plan proposal A ought to be adopted (‘Conclusion’, a deontic D- claim
because
Plan A will imply or result in effect B (Factual-instrumental FI premise )
And
Effect B ought to be pursued” (Deontic D- premise)
Summarized as D(A) since {(FI(A)B) & D(B)}.
A more elaborate version would include a premise stating the conditions C under which it is assumed that the factual-instrumental premise would apply:
D(A) since / because { ((FI A B) & D(B) | C) & F(C)}
Or
A ought to be adopted
Because
A will result in B given conditions C
And
B ought to be pursued
And
Conditions C are (or will be) given.
I was led to this because sometimes the third premise is present in actual arguments, often just in terms such as “Given the circumstances” or ‘In the present state of affairs…) , but an argument could be made that this is really an argument supporting or questioning one of the other premises: ‘We can’t implement A because the needed resources just aren’t available to achieve B”.
* The arguments do not have to (I suggest should not) be labeled as ‘pro’ or ‘con’ (other than perhaps as ‘intended’ by the author) because, as will be seen below, whether an argument is perceived as a pro or con by an individual, depends on the individual’s assignment of plausibility judgments to the premises.
* While the discussion may pursue the questions of supporting evidence or argument for any ot the premises, the assessment of the set of all arguments will begin by individual participants assigning
a) plausibility judgments pl to all premises of the arguments (that can be seen as probability judgments for FI and F premises), on a scale of e.g. -1 to +1, and
b) weights of relative importance w, of the deontic premises in each argument, with the weight w(i) for deontic claim in argument i: 0 ≤ w(i) ≤ 1.0 and ∑w(i) = 1.0 of all deontic claims in the entire set of pro and con arguments.
* For each individual participant:
– The plausibility Argpl(i) of an argument i will be some function of the plausibility judgments the participant has assigned to the premises of that argument; e.g.
Argpl(i) = ∏{Prempl(j) of all its premises, or Argpl(i) = MIN(Prempl(j ): the argument is as plausible as its least plausible premise.
– The weight Argw(i) of argument i is a function of its plausibility and the weight w(i) of its deontic premise, e.g. Argw(i) = Argpl(i) * w(i).
– The plausibility of the proposed plan (for an individual) is then a function of all argument weights: e.g. Planpl = ∑(Argw(i) for all n arguments I considered.
* For the task of generating an acceptable ‘group” plausibility statistic to determine the group’s decision, each group or constituency will have to agree upon some such statistic, e.g. the average Planpl and a decision threshold for acceptance of a plan. There are several possibilities. For example, it could be agreed that the group’s average Planpl should be at least positive (on the -1/+1 plausibility scale), or that it should be the highest one of several alternative ‘plans’ including the alternative of ‘doing nothing’, or a consideration of the range of plausibility values for individuals or subgroups (taking care of the ‘worst-off’ parties affected by the problem to be remedies and by proposed plan(s). This important and controversial issue is beyond the scope of the issue at hand here – the treatment of pro and con arguments in the planning discourse.
Whether these or similar provisions for collective design, planning, policy-making discourse can or should be applied to all ethical, moral, political discourse, is another much needed discussion. For now, just one significant implication of this view — that any measure of plausibility merit of social plans must be based on the distribution of individual judgments of affected or concerned people, not some general or universal ‘truth’ or validity — should be noted: For any application of AI tools to collective decisions about controversial plans, is there any plausible basis for an AI system to make even recommendations for such decisions, unless the data base for its algorithms includes the individual plausibility and weighting judgments of all human participants in the discourse? That is, much as machine assistance will be needed for the discourse of large or global planning projects or decisions, the AI tools or systems must be integrated into the human discourse and compute its results with the human judgment data as they evolve during the discourse. They cannot substitute for the discourse.
Such implications may be lurking in the background for the theoretical discussions of arguments, whether deductive, inductive, or conductive. They must urgently be pulled out from the background into a human ‘planning–type’ discussion of its own.
Notes:
[1] At the time of my first efforts in this (the early 1970’s) I was not aware of Wellman’s introduction of the term ‘conductive’ for these arguments but was disappointed in the modal logic and deontic logic sources. There was some discussion whether they should be considered forms of ‘abduction’ (in Peirce’s sense). But the common understanding of abduction also did not seem to match the kinds of arguments I saw in the planning discourse. Abductive reasoning can play a role in the development of solution proposals, however, but not in the weighing of those different solutions.
[2] The statement simply combines two considerations, one ‘pro’, one ‘con’, which simply means that it offers two separate arguments to two different ‘conclusions’ or action proposals, as rudimentary enthymemes, with the ‘though’ wording also indicating that one of those reasons, however admittedly plausible, should be assigned less ‘weight’ than the other. I do not see any rationale for the desperate suggestion in one of the branches of the treatment decision tree, to consider the ‘counter-consideration’ as an implied part of the ‘conclusion’. Some necessary assumptions would also be necessary, for example that the only time period available for the two actions is the same (so that e.g. mowing the lawn might be done before going to the movie, or, why not …tomorrow?
The implication is that for a systematic evaluation, the two arguments for the two different proposals must be stated separately, with all the missing premises made explicit, and that participants then add their individual evaluation judgments to all the premises.
Similarly, the popular ‘informal logic’ recourse to the Toulmin argument pattern with its backing and warrant components did not seem appropriate for planning arguments: the pattern seemed to somewhat arbitrarily select its components from premises of ‘successor issues’ arising from efforts to support or question the basic premises of the ‘planning argument’ as I perceived them.
Preparing to get some payments for my share in the second home I sold in Europe, I started to look at investment possibilities here in the US. The first attempts at doing so were rewarded with an avalanche of promotion emails and FB posts selling investment services, So I looked at some of those to find out more.
What I saw was an astounding similarity in their promotion material. They all asked me to watch videos — of unspecified length, so I never knew how much time I would have to devote to listen to them. Not all of them offered transcripts of those videos for hearing-challenged folks like me. But they all lure prospective viewers with the promise to reveal some incredible secret, and then devote much time and space to ”first introducing themselves” and showing a lot of ‘predictions’ of crises or events they claimed to have made, and resulting investment earnings diagrams that — surprise — all show the same angle from almost nothing to current levels of stock or crypto prices or capitalizations. Which of course, if one knows just a little about making such diagrams, can be manipulated by choosing different scales for the x and y-axis of those diagrams, makes one wonder how stupid and gullible they think we are… Let me tell you a secret: if you start a diagram with the initial stock price of zero or almost zero (which is where most of them start) any price after any time span will produce a close to potentially infinitely high ‘profit rate’! (Potential, that is, if you can sell it… That’ll be $2.50, thank you) .
The killer, however, is the common pattern of selling the services: first claiming the amazing ‘value’ of their service programs and then making the incredible generous offers of reducing the initial three-or-four-digit price down to something like $49 or $39 for the ‘basic’ version. (‘Ending tonight!) And before even getting to the final checkout for that purchase, taking up ore time with offers of ‘lifetime extensions’ and other service blends. Which makes one wonder, again: don’t they realize that one wants to try out the quality of such a service before buying more of them? Huh? So those offers should be launched at customers after some time of proving their ‘value’.
Now I’ll admit that those videos and ‘reports all are done up very smartly and convincing, obviously not cheap. But doesn’t this raises more questions?: why are those folks so desperately eager to sell such two-digit services if they could make so much more money by investing the cost of those videos and websites and promotions in the investments they are promoting (or promise to reveal)? Because the first result of some purchases of basic services are just more videos, (including endless repeats of the very videos that conned the customer to buy the service in the first place), fear-raising webinars for additional fees, more service programs and ‘reports;’ and very little actual useful information for novice prospective investors. Inbox overflow. The promised ‘professional customer service teams’ don’t even bother to respond to questions…
It could drive a poor advice-seeking fellow to drink, For a modest fee, I’ll reveal the brand to respondents so y’all can invest in the company, whose shares are going to rise — in up or even in down market conditions, guaranteed!
Psst: Any reader out there producing adequate Sonoma Zinfandel libations: here’s a hot innovative tip: Insert a currently cheap but promised to-rise altcoin token recommendation under the bottle cap to lure more investment-advice-seeking consumers. It must be discovered fast before the price goes up: get it? (You don’t want any of those guys who buy wine to keep for decades.) With the profound insights I have gathered, I can promise that advice for just a guaranteed monthly delivery of a case…
The claim we want to examine, as stated by proposed approaches (methods, techniques, perspectives): “This approach can be used to tackle WP’s” seems to accept the understanding of WP’s — the original Rittel/Webber one or a slightly different one of later interpreters, as well as a common understanding of ‘tackle‘ as not only ‘trying’ but actually achieving the development of a ‘solution’ to problems described as WP’s: ‘solving’ such problems. It was already pointed out in the first post of this series that of course any group is entitled to ‘tackle‘ (understood as ‘tryingto solve’) any problem with any approach it deems appropriate. The question then is whether the claim actually can be seen as a believablepromise that a problem with the WP properties will be solved usingthe approach or method. (The possibility that the very concepts of ‘problem’, WP, ‘solving’ these, etc. might themselves need critical scrutiny was be taken up in a the second post of the series).
So what are the criteria that might be used to determine the merit or validity of a claim of the above nature? Put crudely: what would make a client confident to hire a company using an approach X claiming that the approach will solve the client’s WP? Would a first step be to look for answers to the question of how the proponents of the approach would respond to each of the mutually accepted and understood WP properties? Two questions:
a) If the respective property is seen as a significant obstacle to the achievement of a solution‘ to WP’s, what will enable X to overcome / respond to that obstacle?
and
b) What if the WP property is serious, what are its implications for application of approach X? E.g.: If the property requires an adaptation of the approach or the general understanding of ‘solution’: what would those adaptations look like?
What other critical question might be asked? The attempt to examine a few competing approach ‘brands’ might help improve this first set of questions.
The examination of the answers — their generality or specificity, the strength of supporting evidence or argument, and fit to the problem at hand — might help to assess the merit of the claim, even if it may not be sufficient to establish a sound basis for preferring one approach X from a competing method Y. This is, in essence, an invitation to entities aiming to work on the world’s WP’s, to contribute their response.
Not being a representative or promoter of a particular ‘brand of this kind, but feeling obliged to offer an example of what answers to these questions might look like, I will sketch a few sample answers from a less controversial ‘approach’: the predominant political parliamentary process. The answers are not intended as a comprehensive set of possible responses, but to clarify what such responses might look like, and start the discussion:
Some potential responses of the ‘parliamentary process’ (‘PP’) as a problem-solving ‘approach’, to the WP properties:
No definitive problem formulation
The PP accepts ‘problems’ on its ‘agenda’ as the justification for proposed ‘solutions’ in the form of proposed ‘bills’ that aim to remedy them. That is, problems statements dealt with as stated by the legitimate participants in the process (elected representatives of defined constituencies). Such statements may be questioned and debated in the subsequent discussion prior to a decision. That is, the issues of what problem formulations will be entered for discussion and consideration is entirely the task of the participants (though they may be responding to statements in the media and public domain).
Every wicked problem is essential unique:
Each ‘bill’ for legislative action is accepted without regard to its uniqueness or similarity to other cases, though it may have to be stated in formal terms defined by procedural rules, terminology, and conventions.
Any ‘solutions’ for WP’s are not ‘correct’ (true) or ‘wrong’ (false) but, in the opinions of affected parties, ‘good’ or ‘bad’.
The terms ‘true or false’, ‘good, bad’ etc. may be used in the discussion of proposed measures, but the outcome of the process is (sidestepping this issue?) is simply ‘accepted’ or ‘rejected’.
Every WP can be explained in many different ways, but can also be seen as part of, or as a symptom of another problem or set of problems.
The debate offers the opportunity for presenting such considerations. The issue may best be included in provisions or justification statements for introducing bills for decision: these should include evidence of having explored different explanations or underlying problems of which the stated reason of the bill could be a mere symptom.
While the issue of ‘tests’ (or their substitutions by systemic prediction or simulation models) may be and perhaps ought to be more forcefully entered into in the debate of a proposal, the viability of proposed legal actions is left to the judgment of each participant. (In theory, unless constrained by factors such as ‘party discipline’).
There are noimmediate nor ultimate testsfor the goodness or appropriateness of proposed ‘solutions’.
There areno well-described and finite sets ofadmissible operationsthat can be brought to bear on WP’s.
If this means that the process should deliberately be kept open to new ideas and ‘operations’, it of course applies to the phase of development of solutions before they are presented to the decision-making body for approval or rejection, which then does rely on agreed-upon procedural rules. The debate itself remains open to offering new ideas, or they may be assigned to special groups for more systematic analysis.
There is no enumerable set of potential ‘solutions’to a WP: the ‘solution’ space is infinite and multi-dimensional.
In PP practice, solution proposals are simply presented to parliamentary bodies for approval. The debate may make claims of having explored the entire solution space, but the support for such claims and their counter-arguments must be judged by the participants. Claims of there being ‘no alternative’ to proposed solutions are always flawed and should be avoided: there is always at least one alternative: that of ‘doing nothing’.
WP’s have no inherent ‘stopping rule‘ for efforts to deal with them.
This being true for all possible approaches, the question becomes one of adopting meaningful and practical ‘problem-external’ stopping rules. Common examples in parliamentary bodies are the rule of ‘no more comments / objections’ serving as triggers for proceeding to the decision-making (e.g. voting) phase, or agreed-upon simple time limitations. Provisions like the ‘filibuster’, pretending to ensure that there will be enough time to present ‘all’ concerns for ‘due consideration’, should be amended with rules preventing mere repetitions of arguments already heard.
Every WP is essentiallyunique.
This feature should be seen as a warning against relying exclusively on precedent cases for the justification of proposed solutions: again, it is a suggestion for the debate to explicitly examine the unique aspects of the problem the solution claims to address.
Every effort to deal with a WP is a ‘one-shot operation’
Like other WP properties, in the PP, this should be seen as ‘stock’ reminder for the debate to address.
The WP-planner has ‘no right to be wrong’ (as in ‘trial and error’) but is liable for the outcomes of any actions taken.
The issue of accountability for actions taken or not taken by parliamentary bodies is a perennial one. Traditional provisions of holding representatives or officials by the threat of denying re-election, or (for more egregious issues: removal from office) arguably are in need of improvement. Especially in view of other rules such as term limits: If representatives can only one serve a single term, or two terms, there is no accountability remedy for flawed actions during the ‘last’ term. There is no logical reason against the parliamentary system making such improvements.
* The‘distributed information’ feature of WP’s:
This admittedly serious issue is one that should — and arguably can — be addressed in the provisions for preparation of action proposals (bills) to parliamentary bodies.
* Nonlinearity, ‘loops’ and counter-intuitive patterns in the behavior of the system affected by a proposed action:
Like some other assessment aspects (such as quantitative measures of performance of proposed solutions), this issue may not be sufficiently well dealt with in traditional parliamentary debate: Rhetorical debate arguments tend to focus on simple cause-effect relationships, and — for quantitative issues — highly aggregated but therefore abstract indices such as ‘growth’, ‘Gross National Product’ or ‘Deficit spending’. Systemic analysis and representation of complex systems aspects should be made required components of the preparatory justification documentation of proposed bills, together with provisions for sending proposals ‘back to the drawing board’ to include new and insufficiently detailed concerns brought up during the debates, or in outside public comments accompanying the debate.
* The ‘doorknob’ syndrome:
This aspect is related to the ‘WP as a symptom of other problems’ feature. It should properly be dealt with in the preparation phase of bills, with a summary of its treatment in the justification documentation.
* Making decisions on behalf’ of others, such as actually affected parties:
In the PP, this question is addressed by the assumptions
a) that by constituencies electing their leaders and representatives, thereby entitle them to make decisions on their behalf, and
b) that conflicts of interpretations in the constituency as well as conflicts in the decision-making body are adequately settled by majority rule voting.
It must be admitted that these provisions do not meet the aim of ‘acceptable’ or ‘desirable’ design for all parts of the constituency. In fact, the majority rule (in all its variations to ensure more fairness) allows all concerns of the voting minority to be summarily dismissed. The remedies for this are seen in the ‘re-election’ provisions — calling for efforts to develop better ‘accountability’ tools (as discussed above).
* The ‘making a difference’ syndrome:
Contributing to the uniqueness of WP’s, this aspect can be seen as not adequately served by the rules of the PP. It must of course be balanced against the necessity for agreed-upon procedures that can be fairly and equitably applied to all similar public projects. Such common rules include the principle of separating the ‘projects’ of generating and reaching agreement on general project rules from the specific planning projects to which those rules apply. Specific ‘unique’ aspects of individual projects may require exceptions or modifications of the general rules. (To prevent conflicts that could derail constructive planning projects, the general rules must and can contain provisions for such possibilities). Individual participants’ desire to ‘make a difference’ will mainly be constrained by such rules in the main decision-making phases of the PP, but arguably can find opportunities for creative application in the preparatory and support activities.
Summary observations:
This tentative discussion suggests that while the Parliamentary Process as practiced may fall short of adequate provisions to avoid pitfalls related to some WP properties, but that needed improvements are quite possible. A common denominator is that such improvement provisions will be situated in preparatory activities such as developing the specifics of plans and other support functions, before the final plans are presented for approval in the main decision-making phase. This may remain a problem, because any such supplementary functions may or may not be called upon, at the discretion of the ‘official’ members of the main decision-making assembly.
Another potential problem of the parliamentary process — common to many other ‘approaches’ — is that the final decision-making tools such as majority voting have the potential of marginalizing or entirely ignoring many of the contributions and insights achieved in supporting and preparatory activities, and even overriding key concerns of minorities, in the main decision body. This feature of common planning and policy-making is not addressed in the WP ‘properties’: Should this issue be included in that set, or be seen as a separate but ubiquitous wicked problem that affects many or all other WP’s?
The Parliamentary Process, in its many forms, currently is a main governance planning tool, up to the highest international institutions. Can it be expected to be easily and smoothly replaced by a ‘better’ system any time soon? The main competitive ‘approach’ currently being authoritarian rule, which arguably offers few assurances for meeting the PP promises of ‘listening to all concerns and give them all due consideration’ in making decisions, much less guarantees for attending to WP pitfalls. (But it may deserve a chance to present its case, not just to violently take over?)
Barring convincing demonstration that a better approach will emerge, is the best hope we have that meaningful improvement provisions such as those related to the concerns expressed in the WP (and others!) can be integrated into the PP structure? A wide, structured, and thorough discussion of other competing ideas is urgently needed, and it should include the response of each approach to the Wicked Problem features.
RE-EXAMINING WICKED PROBLEMS: UNDERSTANDING AND IMPLICATIONS
Thorbjørn Mann 2021
This is the second post on the question of claims by proposed problem-solving ‘approaches’ to successfully ‘solve’ Wicked Problems.
Looking for reassuring answers to the question whether some approach, method or ‘perspective’ can be expected to live up to claims that using the respective approach will reliably result in ‘solving’ Wicked Problems, it may be useful to turn the question around and look at the concept of ‘wicked problems’ itself, and its understanding. Are its ‘properties’ and implications really justifying the frequent automatic rejection of such claims, or claims of a technique guaranteeing solutions? The following first attempt, for discussion, takes a stab at this question, examining each of the WP properties:
* “No definitive problemformulation”:
This feature reflects the fact that different people involved in a project will have very different opinions about the problem, and that the acceptance of one view of ‘what the problem really is about’ is a choice or decision. It is a stern challenge to the habitual recommendation to begin a problem-solving process with a ‘clear statement of the problem’. The implication: to avoid controversies and disruption from occurring later in the process it is necessary to not only begin such a process with a widely open invitation to affected and interested parties to contribute many different perspectives of the problem, but to keep the process open to emerging insights on this issue.
* “Every WP can beexplained in many different ways”:
The same recommendation holds for this WP property:
* “Every WP can be seen as a symptom of another problem or set of problems.”:
One obvious implication of this feature is that any proposed ‘solution’ idea, however promising, can be dismissed as ‘only treating the symptom’. The question should therefore be raised early in the process to be discussed, and any necessary decisions resulting from it agreed upon – such as having to shift the entire effort to a different institutional level or entity – before devoting much time and energy to develop a ‘symptom-treating’ solution.
* “Every wicked problem is essentiallyunique”:
The implication of this feature is that ‘tried-and true’ methods and lessons from previous cases may not be applicable to a new WP. However, could it be that the stark formulation of the property unnecessarily hides the fact that the significance of similarities and differences between the new problem and similar cases are a matter of degrees? There may be part of the problem that are sufficiently ‘similar’ to warrant the application of known tools. The process should address this question by looking at details and make decisions about using known methods where applicable and devote efforts to develop new tools as needed.
* “WP ‘solutions’: not ‘True or False’ but ‘Good or Bad’:
This reminder was especially necessary at the time the WP issue was raised and published: there was a veritable movement of stressing ‘fact-based’ decision-making, that is, using ‘objective facts’ about a proposed solution’s measurable performance as the decision criterion. This trend seems to re-emerge periodically, (under slightly different banners such as ‘science’ or ‘expert advice’), perhaps because of inappropriate populist switching to decision-making based on ill-informed intuitive ‘goodness’ judgment or insistence on ideological principles decrying the facts presented by discipline experts as ‘elitist oppression’. So the reminder should perhaps be revised to reflect that the real issues are
– the selection of the performance measures for which the ‘facts’ are then established – of course factual information must be provided and assessed for any problem, wicked or tame;
– these ‘facts’ will always be qualified by probability; especially the predicted ‘facts’ offuture solution performance (which of course aren’t even facts yet!); and
– the necessity of communicating about how fact-measurements and predictions relate to the ‘good’ or ‘bad’ judgments (the process Rittel called by the somewhat problematic name of ‘objectification’); and
– the most important question of whose judgments should determine the common decisions about accepting or rejecting proposed ‘solutions’.
* “No immediate nor ultimate tests”:
This property refers to the difference between scientific hypothesis-testing and the discussion of proposed plans to remedy social problems, as well as to the feature that plans and policies will have chains of consequences that make ‘immediate tests’ meaningless even if we had such tests and ‘ultimate tests’ un-specifiable because the time span of those consequences is indefinite. However, any reaction of doing without any ‘testing-like’ efforts is seriously mistaken. Two considerations:
– Simulation models used properly (that is, to explore the possible consequences of different actions and strategies taken today) can be considered a kind of test or better ‘evaluation’ – the best tools we have for predictions, none of which are establishing true facts since they all deal with future developments: probabilities. And
– Argumentative discourse: The sharing and assessment of the proverbial ‘pro’ and ‘con’ arguments about proposed plans.In which simulation model results may play a significant role, but the essential difference is that planning arguments contain the ‘ought’ premises that are not properly assessed as ‘true’ or ‘false’ and thus the same ought claim may be ‘plausibly’ seen as ‘ought’ or ‘desirable’ by some affected parties but as ‘not desirable by others. The degree to which a plan is perceived as achieving the ‘ought’ state (of a problem perception) is the basis for ‘good’ or ‘bad’ judgments of the plan.
I have suggested that to Popper’s advice about scientific hypothesis-testing:
“We are entitled to accept a hypothesis as corroborated (only) to the extent we have done our very best to show that it is false, plausible and it has survived all those tests”
the closest analogous ‘test’ we have in design and planning is the following:
“We are entitledto accept a plan as plausible and ‘supported’ (only) to the extent we have done our very best to expose it to all the most plausible counter-arguments (‘cons’) and those have all been shown to be flawed or outweighed by supporting arguments (‘pros’).
Evaluation procedures and approaches to develop measures of plausibility of individual judgments of planning arguments have been described, as the closest we have to ‘testing’ plan proposals.
* “No well-described, finite sets of admissible operations”
This feature is set against disciplines like mathematics where the operations of addition, subtraction, multiplication, division etc. are the admissible operations that define ‘tame’ problems. It warns that approaches attempting to specific a finite set of such operations for WP’s are liable to encounter new ways to tackle them – ‘anything goes’ if it works.
* “No enumerable set of potential solutions to a WP”:
The insight that the ‘solution space’ for WP’s may be infinite and impossible to define implies that claims of finding ‘optimal’ solutions are meaningless: there may be even better solutions somewhere in regions of the solution space that were not explored. This constrains the discussion to the more modest quest for solutions that are ‘good enough’ within the regions an approach is able to examine: a feature that was earlier proclaimed as ‘satisficing’?
* “No inherent ‘stopping rule’ for efforts to deal with WP’s”:
The implication of this feature is simply that stopping rules for efforts to tackle WP’s are not provided by the problem itself but by constraints outside the problem but acting on the task force working on it – and as such ‘arbitrary’ and debatable: financial and time constraints being the most common such limitations. For the problem itself, ‘we can always try to do even better”.
* “Every effort to deal with a WP is a ‘one-shot operation’”: and
* “No ‘trial and error’”:
These two properties are intimately related. We cannot rely on the trial and error strategy to learn how to ‘solve’ a WP: Any actions on the problem itself will expend resources, generate new consequences: the ‘next trial’ will now be a very different problem.
* “The WP-plannerhasno ‘right to be wrong’:
Like the hypothesis-testing issue above, this aspect refers to a fundamental difference between science and WP-planning. The scientist having performed a test that refutes a hypothesis may be disappointed — but that is making a legitimate and rightful contribution to scientific knowledge. The would-be WP- solver failing to remedy the problem is actually ‘making things worse’. The plausible implication then is the call for holding the planner – or the decision-maker for the implementation of the plan liable’ — ‘accountable’ — for the failure. More often than not, such calls are rather meaningless, if there is no ‘account’ involved (other than perhaps a decision-maker’s position or ‘reputation’: how does it balance suffering of people affected by the problem of the wrong solution?). Should efforts be devoted to finding better ‘accounts’ for this issue? Rittel suggested one implication: the ‘complicity model’ of planning. Taking this aspect seriously, no decision-maker would be able to accept responsibility for major decisions if it required ‘investments’ equal to the risks of failure of plans. It would be necessary to find ‘accomplices’ willing to share that risk. Again, what kind of ‘account’, what ‘currency’ might be used for this? (I have sketched one possible idea: the use of the ‘reputation’ account of ‘merit points’ earned for the value of contributions to the public discourse to have decision-makers ‘pay’ for important decisions.)
* “Distributed information”:
This issue refers to several aspects of large public WP’s:
– The need to assemble ‘factual’ information about how the problem – and any proposed solutions — affect many different parties ‘out there’ – that are not yet documented and certified in knowledge bases and experts’ knowledge. This may require research and information-gathering for which the need will only become apparent as the discourse proceeds, so that initial estimates of needed resources will be unreliable; and initial surveys to gather such information will be insufficient: the questions to be answered will only emerge later on: the information-gathering effort must accompany the process throughout;
– The question of ‘getting ‘ the information may require offering some incentives for people to contribute it – early enough to be useful (rather than complains after the fact) – and mechanisms for assessing its truthfulness or validity;
– If the property of ‘not true or false but good or bad’ is valid, and thus should determine the decision, these judgments will have to be the judgments of the affected parties. This will require a clear distinction between ‘factual’ information (that must be ‘verified’) and goodness/badness judgments that must be accepted as individual’s assessments and aggregated into overall statistics of sentiments of approval or disapproval. This task is not adequately addressed by many ‘approaches’; the effort to achieve consent or even consensus in small task groups seems to sidestep rather than systematically and transparently confront it. (See also the issue of ‘making decisions ‘on behalf of others’, below.)
* “Nonlinear and counter-intuitive system behavior”:
It is the merit of ‘systems modeling’ to bring this issue to the attention of planners and decision-makers. The simulation models aim at overcoming the resulting prediction difficulties of this ‘complexity’ of the systems involved in WP’s. The connection between the prediction results and the ‘goodness’ judgments (of the many affected parties) has not been sufficiently well explored much less convincingly resolved.
* “The ‘doorknob’ syndrome:”
The warnings against getting lost in the upward or downward ‘cause’ or ‘symptom’ issues of WP’s are understandable but carry the risk of under-estimating the reality and significance of such relationships. The rules that can guide decision about how much attention to devote to them, like the ‘stopping rules’ discussed above, are often extraneous to the problem – which can lead to flawed decisions.
* “Making decisions ‘’on behalf of others”:
Governance and planning decisions on public issues have traditionally been taken by leaders, officials, or representatives of the community, with the justification that these decision-makers are sufficiently familiar with their constituencies to make decisions ‘on their behalf’. This can mean one of two things: Either they know (or claim to know) ‘what’s best’ for the community — even if there are people in the community who disagree — or they know the basis of judgment (the way the community members relate their goodness judgments to the facts of the matter) well enough to make judgments ‘as the people themselves would’. Both assumptions have been questioned, and current efforts to validate either assumption are cumbersome and unconvincing, adding to the wickedness of the problem at hand.
* “The ‘making a difference’ syndrome”:
Many people are perfectly content with the provisions of planning decisions being made by leaders, officials or hired consultants: delegation of work allows us to focus on ‘our’ work and priorities. But to the extent people are – in the name of ‘citizen participation’ – becoming more extensively involved in public problem- solving issues, this makes that involvement a part of their lives, in which they may want to ‘make a difference’ – a somehow outstanding contribution. Consciously or subconsciously, this may mean ‘doing things differently’ from the way things have been done, or from what some recommended ‘approach’ or method is proposing. The planning process itself becomes a part of the plan, and they want to make it ‘theirs’. Regardless of how appropriate or allowable this may be in the view of other participants or approach promoters, this will introduce unforeseen complications into the process. If it is seen as part of these individuals’ ‘right to pursuit of happiness’ – that governments are supposed to ensure: should all public planning efforts include provisions for such efforts – and what would they look like?
There may be some commonalities of implications in these properties that are not apparent in the individual items, and that deserve closer examination. One such common assumption is the reference to the ‘WP solver’. Is this an unspoken and unquestioned assumption of a single designated person or team to do the problem-solving ‘on behalf’ of the community affected? The reality of public projects is that there are always multiple institutions with various decision-making responsibilities – the task then also involves the organization of constructive coordination between all these entities.
A larger common aspect is that meaningful response to WP properties requires some common communication and coordination platform. For all the progress of information technology over the last decades, an appropriate and effective platform for this purpose remains to be developed.
The platform, finally, will also be the venue for reaching decisions. None of the WP properties mention this explicitly, but their implication is that the traditional decision-making modes (such as voting) do not meet the expectations of suitable responses to the issues – e.g. being based on transparently explained individual ‘goodness’ judgments. Especially for problems transcending existing governance boundaries with different decision-making entities and rules, this will become an urgent consideration.
Are these sketchy observations indicating an urgent need for wider discussion?